Docker容器网络解密
涛叔Docker相信大家都不陌生。但Docker基于的容器技术估计好多人都不怎么了解。最近看了一篇关于容器网络的文章Container networking is simple,感觉写的非常好,通俗易懂。文中的内容我基本都知道,但没能像原作者那样总结整理出来。我照着原文操作了一下,也有了自己的体会。今天就结合原文和自己的实践跟大家讨论一下容器的网络原理。
网络名称空间 network namespaces
这个网络名称空间有点不太好理解。linux内核为提供了网络功能,我们可以为每一块网卡设置不同的IP地址,为系统设置特定的路由规则,还可以通过防火墙限制不同类型的网络流量,再一个就是通过tcp/udp跟外界进行通信。所有的这些功能都是linux内核提供的(我们可以通过一些用户态的工具修改参数),我们把网络相关的所有一整套功能统称为网络协议栈。
一般来说,一般操作系统有一套网络协议栈就够了,所有的进程都用。显然linux不一般。理论经上linux可以有无限套网络协议协议栈。每个协议栈都可以为各自的网卡、路由表、防火墙规则等等。不同的协议栈之间是相互隔离的,看起就想两台电脑的网络协议栈一样,互不干扰。
我们也给一整套网络协议栈取了个名字叫网络名称空间。独立空间嘛,互不影响。
好了,让我们做一个小实验,实际感受一下这个空间。所有操作均需要通过root帐号执行哈。
首先查看一下你的网络设备,我们统一使用 iproute2 工具包
# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff
altname enp6s18
altname ens18
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff大家可以看到我有三个设备。第一个叫 lo,也叫回环设备,用于本地通信。第二个我机器的网卡。第三个是 docker 为容器创建的虚拟网络设备,现在先不展开,下面会讲到。
现在我们新建一个网络空间
# ip netns add netns0netns 显然是 net namespace 的简写。add表示新建,后面跟空间的名字。然后,我们可以查看一下新建的空间
# ip netns list
netns0如果创建了空间却不能进去,那不是毫无意义吗?让我们进去看看。这个时候我们需要使用nsenter命令。从名字上就能看出,这是 namespace enter 的简写。nsenter 除了可以进入不同的网络空间外,还可以进入其他一些空间。我们这次只说网络空间。
# nsenter --net=/var/run/netns/netns0 bash显然,--net参数是为了指定网络空间的入口。在linux下,每个网络空间都有一个类似于文件的入口。通过ip netns add创建的入口都在/var/run/netns这个目录下。
最后面的参数是bash,意思是进新的空间并运行bash程序。这个时候我们再查看一下网络设备
# ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00发现问题了没有?这次只有一个 lo 设备了。如果你试着访问外网,你会发现不通
# ping 8.8.8.8
ping: connect: Network is unreachablenetns0是一个完全独立的网络空间,它跟空间外的网络栈的关系是这样的
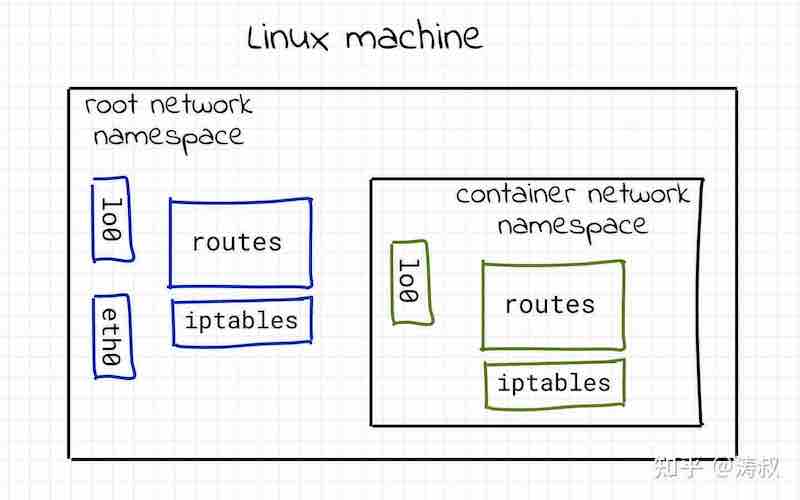
你需要给它「安装」网卡、配置IP地址、设置路由,才能在这个空间中访问外网。那要怎么做呢?我们需要虚拟网卡 virtual Ethernet devices (veth)。
虚拟网卡 virtual Ethernet devices (veth)
物理网卡很好理解,就是电脑上插网线的设备。虚拟网卡要怎么理解呢?喜欢刨根问底的同学可以查询man veth。简单来说,一个veth就好多两块已经通过网线连接到一起的网卡,只要你把它的一端「插」到电脑A,另一端「插」到B,A跟B就能通信。
我们可以创建一个veth设备,将它的一头「 插」到根空间(默认的),另一头插到netns0就能实现两者的通信。lets go。
# ip link add veth0 type veth peer name ceth0这里用到了 link add 命令,veth0 是 veth 设备一端的名字;类型不用说,通过 type 指定为 veth;另一端的名字则是通过 peer name 指定,这里是 ceth0。名字可以随便取,没什么关系。好了,我们看一下新建的 veth 设备长什么样。
# ip link list
...
4: ceth0@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 82:e6:ad:77:f8:c3 brd ff:ff:ff:ff:ff:ff
5: veth0@ceth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether d2:3d:cf:5d:16:5f brd ff:ff:ff:ff:ff:ff大家看到了没有,一下子多出来ceth0@veth0和veth0@ceth0两个设备(当然了,都是虚拟的)。它们是一根绳上的蚂蚱。我们随便选一个,将其插到netns0这个空间。
# ip link set ceth0 netns netns0注意,引用的时候不要写@后面的内容。现在我们看一下根空间的网络设备
# ip link list
5: veth0@if4: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether d2:3d:cf:5d:16:5f brd ff:ff:ff:ff:ff:ff link-netns netns0根空间只剩下veth0了,注意最后的link-netns netns0,说明它的另一端连着netns0这个空间。我们再到netns0空间内看一下
# nsenter --net=/var/run/netns/netns0 bash
# ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
4: ceth0@if5: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 82:e6:ad:77:f8:c3 brd ff:ff:ff:ff:ff:ff link-netnsid 0看到ceth0了吧,它的后面是link-netnsid 0,指的是根空间。
接下来我们就可以给veth0/ceth0设置IP地址了。为了方便,我不再重复列出nsenter命令。
# ip link set veth0 up
# ip addr add 172.18.0.11/16 dev veth0
# ip link set ceth0 up
# ip addr add 172.18.0.10/16 dev ceth0因为设备默认都是关闭的,我们首先需要使用ip link set up来开启设备。然后使用ip addr add设置对应的IP地址。
然后,就可以在nsnet0空间内访问外面的根空间了。
# ping -c 1 172.18.0.11
PING 172.18.0.1 (172.18.0.11) 56(84) bytes of data.
64 bytes from 172.18.0.11: icmp_seq=1 ttl=64 time=0.031 ms
--- 172.18.0.11 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.031/0.031/0.031/0.000 ms
# ping -c 1 172.18.0.10
PING 172.18.0.10 (172.18.0.10) 56(84) bytes of data.
64 bytes from 172.18.0.10: icmp_seq=1 ttl=64 time=0.029 ms
--- 172.18.0.10 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.029/0.029/0.029/0.000 ms这个时候的网络拓扑是这个样子的
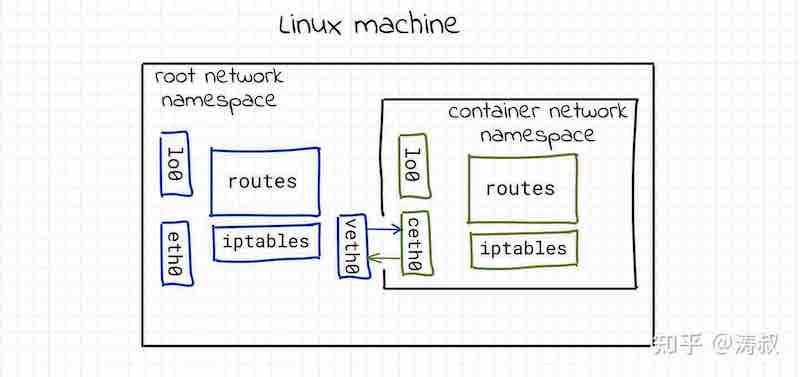
好了,到现在我们有了一个 netns0 空间,而且将它和跟空间连到了一起。我们平时用docker可能需同时启多个实例,这就需要创建多个空间。好,我们现在就再建一个netns1。这次我把所有的命令都写到一起
# ip netns add netns1
# ip link add veth1 type veth peer name ceth1
# ip link set ceth1 netns netns1
# ip link set veth1 up
# ip addr add 172.18.0.21/16 dev veth1
# ip link set ceth1 up
# nsenter --net=/var/run/netns/netns1 bash
# ip addr add 172.18.0.20/16 dev ceth1好了,让我们看看能不能ping通netns1的网卡。
# ping 172.18.0.20
PING 172.18.0.20 (172.18.0.20) 56(84) bytes of data.
^C
--- 172.18.0.20 ping statistics ---
3 packets transmitted, 0 received, 100% packet loss, time 2029ms显然失败了。让我们看一下现在的网络拓扑
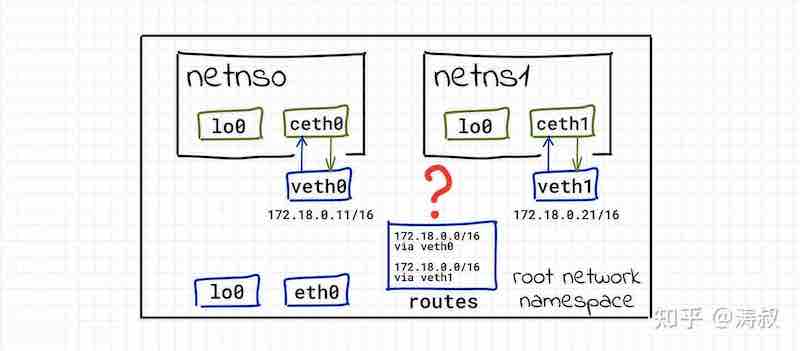
现在根空间有两个网卡,veth0 和 veth1,都属于 172.18.0.0/16 网段。当我们尝试访问 172.18.0.20(也就是 ceth1),内核不知道要使用 veth0 还是 veth1 发送。如果我们在根空间查看路由表,我们会发现两条关于 172.18.0.0/16 网段的路由:
# ip route
...
172.18.0.0/16 dev veth0 proto kernel scope link src 172.18.0.11
172.18.0.0/16 dev veth1 proto kernel scope link src 172.18.0.21内核会使用第一条,也就是把本应该发给ceth1的包发给了ceth0,自然得不到回复。
但这两条路由是怎么来的呢?答案是内核自己猜的。因为我们首先给veth0设了172.18.0.11/16这个IP地址,所以内核认为所有172.18.0.0/16网段的数据都应该通过veth0发送。一般来说这是正确的。但后来我们又加了veth1,并且设置了172.18.0.21/16这个地址。内核又学了一遍,添加了一条路由。
很明显,我们给两个网卡设了同一网段的不同地址,导致网络没法互通。最简单的办法是一个空间用一个网段,但看起来又不那么优雅(一般所有的docker实例共用一个网段)。那怎么办呢?
虚拟交换机(网桥)virtual network switches (bridge)
这个时候我们要请出虚拟网桥了。怎么理解网桥呢?可以根前面的veth类比一下。veth可以看成一网线连接的两个网卡。网桥可以看成是可以连接多条网线的网卡。因为可以连接多条网线,网桥会随时把任意一条网线收到的数据转发给其他所有网线上去。网桥自己也可能会发送数据,这些数据也会发送到所有网线上去。
好了,先创建一个网桥。
# ip link add br0 type bridge
# ip link set br0 up同样使用ip link add,这次的类型是bridge。
接下来,我们需要删除 veth0 和 veth1 上的 IP 地址(不然内核的路由表会影响通信)。
# ip addr del 172.18.0.11/16 dev veth0
# ip addr del 172.18.0.21/16 dev veth1最后,我们把veth0和veth0连到网桥上。
# ip link set veth0 master br0
# ip link set veth1 master br0现在的网络拓扑变成了这样:
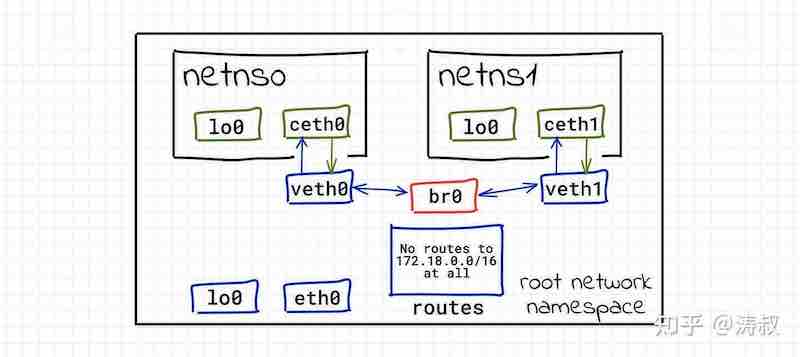
现在两个容器就可以相互通信了。
# ip netns exec netns0 ping -c 1 172.18.0.20
PING 172.18.0.20 (172.18.0.20) 56(84) bytes of data.
64 bytes from 172.18.0.20: icmp_seq=1 ttl=64 time=0.078 ms
--- 172.18.0.20 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.078/0.078/0.078/0.000 ms
ip netns exec netns1 ping -c 1 172.18.0.10
PING 172.18.0.10 (172.18.0.10) 56(84) bytes of data.
64 bytes from 172.18.0.10: icmp_seq=1 ttl=64 time=0.068 ms
--- 172.18.0.10 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.068/0.068/0.068/0.000 ms如果你装了 docker,你会发现容器间ping不通,那是因为 docker 会设一条防火墙规则,只允许 docker0 这个网桥的设备相互通信。
...
-P FORWARD DROP
-A FORWARD -i docker0 -o docker0 -j ACCEPT
...最简单的处理办法是允许所有网桥转发
# iptables -P FORWARD ACCEPT到现在,两个容器之间可以互相通信。但容器跟宿主系统还没能通信。为此,我们可以给网桥br0设置IP地址。还记得前面说可以把虚拟网桥看成一块有多个网口的网卡吗?
# ip addr add 172.18.0.1/16 dev br0
# ping -c 1 172.18.0.10
PING 172.18.0.10 (172.18.0.10) 56(84) bytes of data.
64 bytes from 172.18.0.10: icmp_seq=1 ttl=64 time=0.083 ms
--- 172.18.0.10 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.083/0.083/0.083/0.000 ms
# ping -c 1 172.18.0.20
PING 172.18.0.20 (172.18.0.20) 56(84) bytes of data.
64 bytes from 172.18.0.20: icmp_seq=1 ttl=64 time=0.091 ms
--- 172.18.0.20 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.091/0.091/0.091/0.000 ms好了,现在的网络拓扑变成了这样,几个网络空间都可以相互通信。
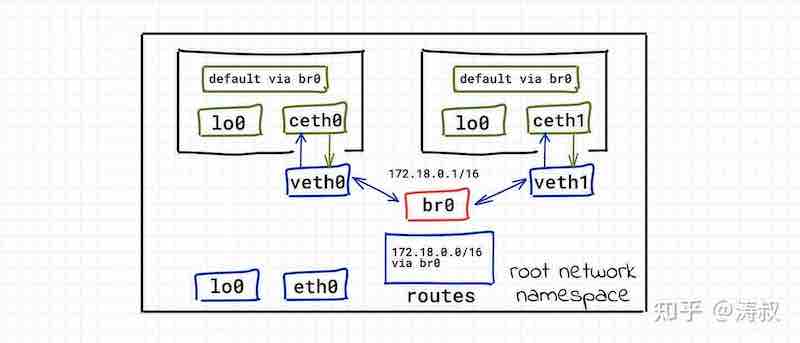
容器可以访问宿主机了,那能访问公网吗?现在还不行。
ip netns exec netns0 ping -c 1 8.8.8.8
ping: connect: Network is unreachable我们可以先看一下容器内的路由表
# ip netns exec netns0 ip route
172.18.0.0/16 dev veth0 proto kernel scope link src 172.18.0.10只有一条关于172.18.0.0/16网段的路由。在容器内不知道该如何访问8.8.8.8。 显然,我们需要认一条默认路由规则,下一跳只能设成172.18.0.1,这是根空间的 br0。要想访问外网,只能借助根空间。
# ip route add default via 172.18.0.1现在的路由表变成了这样
# ip netns exec netns0 ip route
default via 172.18.0.1 dev veth0
172.18.0.0/16 dev veth0 proto kernel scope link src 172.18.0.10但依然没法访问(跟上次不一样,这样是没有回包)。
ip netns exec netns0 ping -c 1 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
^C
--- 8.8.8.8 ping statistics ---
1 packets transmitted, 0 received, 100% packet loss, time 0ms因为设了默认路由。当我们在容器内访问8.8.8.8时,系统会把数据包转发给172.18.0.1,也就是br0。因为br0在根空间,所以br0收到的包需要根空间处理。可是,根空间也不知道如何访问8.8.8.8,它唯一能做的是把包转发给自己的默认路由。但是,这种转发行为默认是不开启的。需要手工开启:
# echo 1 > /proc/sys/net/ipv4/ip_forward这样就完事了吗?还不行,这里涉及到一个地址转换的问题。
路由和地址转换 IP routing and network address translation (NAT)
从 br0 收到的包的源地址都是172.18.0.0/16网段的,显然这个网段跟宿主机的物理网卡(假设是 eth0,假设其IP地址是192.168.0.100/16)不在一个网段。更关鍵的问题是,如果宿主机直接将来自br0的数据包转发给它的默认路由(假设是192.168.0.1),那么192.168.0.1会收到一个目的地址是8.8.8.8而源地址是172.18.0.10的数据包。192.168.0.1根本不知道192.168.0.100上还有一个小网络。所以192.168.0.1一般会丢弃这个包。
怎么办呢?我们就需要让这个包看起来是从192.168.0.100发出来的。也就是说,我们要把这个数据包的源地址改写成192.168.0.100,这就是所谓的地址转换NAT。幸运的是iptables为我们提供了这样的功能:
# iptables -t nat -A POSTROUTING -s 172.18.0.0/16 ! -o br0 -j MASQUERADEiptables 比较复杂,它有很多表,第个表可以有不同的规则,用来控制各种网络数据。其中 nat 这张表就是用来控制地址转换规则的。iptables在转发数据包的时候又分好多链(可以简单理解成一个队列)。内核如果确定了一个包要转发给那个目标地址(确定的过程就是路由的过程),就会将这个包放到 POSTROUTING 这条链上。我们刚才的命名就是给这条链上源地址的网段是172.18.0.0/16(通过-s指定)而且目标地址不需要通过br0转发(通过 ! -o br0 指定)的数据包,统一扔到MASQUERADE这条链上。内核会对MASQUERADE上的数据包做地址转换。
好了,现在容器可以访问外网了。
# ip netns exec netns0 ping -c 1 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=120 time=0.355 ms
--- 8.8.8.8 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.355/0.355/0.355/0.000 ms最后一个问题!外网能够访问容器吗?我们前面说过了,因为外面的世界根本感觉不到172.18.0.0/16这个网段的存在,它们看到的都是192.168.0.100这能机器发出的包。所以外网是没法直接访问容器网络的。
那我们该如何在宿主机外访问容器内的服务呢?我们还是要用到iptables。简单来说,我们需要把访问宿主机特定端口的数据包转发到对应的容器。比如,我们想把访问 192.168.0.100:1234 的 tcp 流量转发到 172.18.0.10 这个容器的 11211 端口,我们可以:
# iptables -t nat \
-A PREROUTING \
-i eth0 \
-p tcp --dport 1234 \
-j DNAT \
--to 172.18.0.10:11211命令跟上面的差不多。因为是端口映射,所以需要指定协议(-p tcp)和端口(–dprot 1234)以及目标(–to 172.18.0.10:11211)。最重要的是转发到 DNAT 这条链(-j DNAT)。
这样,宿主机之外的机器如果访问192.168.0.100:1234,实际上就是访问 172.18.0.10:11211。但是,如果你在宿主机上直接访问 192.168.0.100:1234 还是不通的。为什么呢?因为本机的数据包不会走 PREROUTEING 链,走的是 OUTPUT 链。所以我们需要再加一条规则:
# iptables -t nat \
-A OUTPUT \
-d 154.17.5.11 \
-p tcp --dport 1234 \
-j DNAT \
--to 172.17.0.2:11211好了,到现在我们就从内而外把容器网络的相关知识都梳理了一遍。
docker 的网络空间
如果你装了 docker,你会发现系统会多一个 docker0 的设备,就是我们前面提到的 br0。
如果你用 docker 起了某个服务,docker 就会创建对应的网格空间。但是,你用ip netns list是看不到的。为什么呢?因为 docker 创建的网络空间的入口都在/var/run/docker/netns/,估计是故意不让iproute2看到,免得大家玩坏。
那怎么看 docker 创建的名称空间呢?答案是使用lsns,一看名字就知道是 list namespace 的缩写。linux支持很多空间,我们这次只看网络相关的
# lsns -t net
NS TYPE NPROCS PID USER NETNSID NSFS COMMAND
4026531992 net 130 1 root unassigned /sbin/init
4026532556 net 1 5156 11211 2 /run/docker/netns/a4ef8472617c memcached看到了吧,第一个就是我们的根空间,由 systemd 创建。
第二个就是 docker 创建的一个空间。那怎么进去呢?看第七列的路径。使用nsenter --net=/run/docker/netns/a4ef8472617c就可以进入这个网络空间了。
好了,今天就说这么多吧。其实 docker 还支持其他类型的网络。这些就靠大家自己去探索吧。
参考链接