使用 Envoy 实现服务网格
涛叔现在的 service-mesh 系统都比较完(复)备(杂)。如果是新项目,则可以随意选用。但大家很少有机会从零开始构建大型系统,更多的是在已有的系统上迭代。这就要求大家必需在现有系统的基础上设计 service-mesh 接入方案。
目前我厂大规模使用 k8s,而且开发了自己的配置中心和服务中心。为了试验 service-mesh 而去改动基础系统显然不现实。所以我们制定了一个简单的半mesh方案,可以快速引入 envoy 并试验各种功能。各组件关系如下:
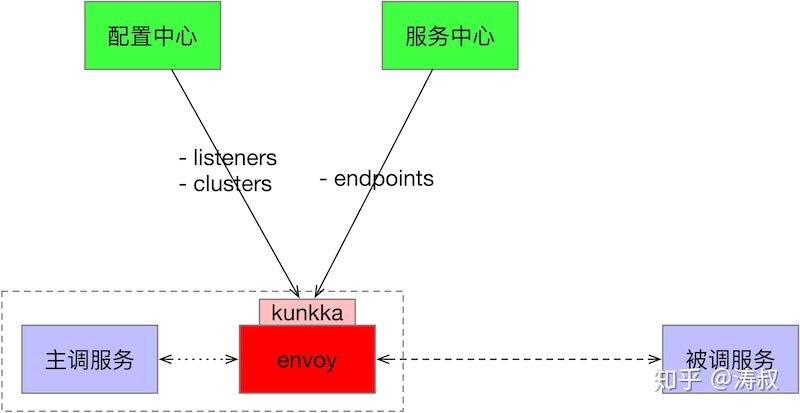
主调服务和被调服务都运行在 k8s 容器,启动后会自动注册到服务中心。每个服务都会配置一个伴生容器(sidecar),跟随服务一同启动。服务之间使用 http 协议通信。
我们知道,Envoy 有自己的一套复杂的配置。如果要充分利用 Envoy 的各项能力,我们还得配置 data panel 和 xDS 服务,这会让系统变得异常复杂。
我们引入了一个简单的 kunkka 程序来代替 data panel 和 xDS 服务。kunkka 的职责如下:
- 从配置中心同步 Envoy 配置,包括 listeners 和 clusters
- 从服务中心同步服务节点
- 启停 Envoy 进程,处理 k8s 信号
Envoy 的 xDS 功能支持热更新大部分配置。因为我们使用了伴生容器方案,如果要引入新的接口或者服务依赖,一定会发布新版本,那么伴生容器一定会跟随重启。所以我们只使用了 EDS,像 listener, route 和 cluster 都是静态配置。
下面是一个配置示例:
static_resources:
listeners:
- name: foo.bar
address:
socket_address: { address: 0.0.0.0, port_value: 3000 }
filter_chains:
- filters:
- name: envoy.http_connection_manager
config:
stat_prefix: foo
codec_type: AUTO
route_config:
virtual_hosts:
- name: foo.bar
domains: ["*"]
routes:
- match:
prefix: /foo/bar/
route:
cluster: foo.bar
http_filters:
- name: envoy.router
clusters:
- name: foo.bar
alt_stat_name: foo-bar
connect_timeout: 0.01s
lb_policy: RANDOM
health_checks:
timeout: 0.02s
interval: 30s
unhealthy_threshold: 3
healthy_threshold: 3
http_health_check:
path: /foo/bar/ping
outlier_detection:
consecutive_5xx: 3
type: EDS
eds_cluster_config:
eds_config:
path: ./foo.bar.yaml在这个例子中我们让 Evnoy 监听 3000 端口,将路径前缀为 /foo/bar/ 的请求转发到 foo.bar 集群。此集群的类型设为 EDS,EDS 配置中使用了 path 属性。这是本方案的关键。Envoy 会监听配置的文件,如果文件内容发生变化会自动加载。kunkka 就是监听服务中心通知来动态更新这个 foo.bar.yaml 的。EDS 文件生成模板如下:
version_info: "0"
resources:
- "@type": type.googleapis.com/envoy.api.v2.ClusterLoadAssignment
cluster_name: {{.Name}}
endpoints:
- lb_endpoints:{{range .Endpoints}}
- endpoint:
address:
socket_address:
address: {{.Addr}}
port_value: {{.Port}}{{end}}大家可以看到,我们目前的方案其实不是真正的 mesh。因为只有主调服务一侧有 Envoy。正常的调用流程应该是 主调服务➜Envoy➜Envoy➜被调服务,而我们的则是主调服务➜Envoy➜被调服务。所以我称之为半Mesh。 之所以如此是因为被调方一般强调服务的稳定性,不会轻易参与这种纯技术上的试验。这也是组织架构决定技术架构的典型例子了。
这种做法的问题:
- 健康检查需要服务专用接口,不然服务实例漂移之后可能出现误调用的问题
- 服务启动时需要等待 Envoy 初始化完成
- 服务停止时需要先停服务再停 Envoy
还有一个方案是在物理机上部署 Envoy。Envoy 不跟服务启停而启停,就不需要处理启停顺序和等待初始化的问题。我个人也觉得这样更合理。但这个方案要求所有配置都都得通过 xDS 下发,而且对 Envoy 发版要求是绝对平滑,不然会影响同一物理机上的所有服务。
就先写这些,欢迎留言讨论。