Go HTTP 服务超时控制
涛叔系统对外提供 HTTP 服务的时候一定要控制好各个环节的超时时间,不然很容易受到 DDos 攻击。我们部门使用的业务框架是基于 Go 语言的 net/http 标准库二次开发的。在当年写框架的时候,我对 Go 语言 HTTP 服务器的超时控制理解还不深刻。觉着只要在最外层加上 http.TimeoutHandler 就足够了。系统上线后也一直没有出这方面的问题,还自我感觉良好。其实是因为我们运维在最外层的 Nginx 设置了各项超时控制,没有把系统的问题暴露出来。等我们在 AWS 上运行另一套业务系统的时候,因为 AWS 的 ALB 配置跟原来的 Nginx 不同,发现只用 http.TimeoutHandler 在特殊场景中会产生「死锁」!我当场就阵亡了,赶紧排查。大致看了一遍 Go 语言 HTTP 服务的源码,找到了死锁的原因。今天就把相关经验分享给大家。我在看代码的时候还发现 Go HTTP 服务器在读到完整的 HTTP 请求后会再起一个协程,该协程会试着再读一个字节的内容。非常奇怪🤔,也一并研究了一下,最终找到了相关的 issue 和提交记录,还发现了 Go 语言的一个缺陷,今天也一起分享给大家。
超时配置
Go HTTP 服务器对应的结构是 net/http.Server,跟超时相关的配置有四个:
ReadTimeoutReadHeaderTimeoutWriteTimeoutIdleTimeout
除了这四个配置外,还可以使用 TimeoutHandler,但这个需要调用net/http.TimeoutHandler()获得,函数签名如下:
package http
func TimeoutHandler(h Handler, dt time.Duration, msg string) Handler以上配置和 TimeHandler 对应的作用过程如下图(来自 Cloudflare):
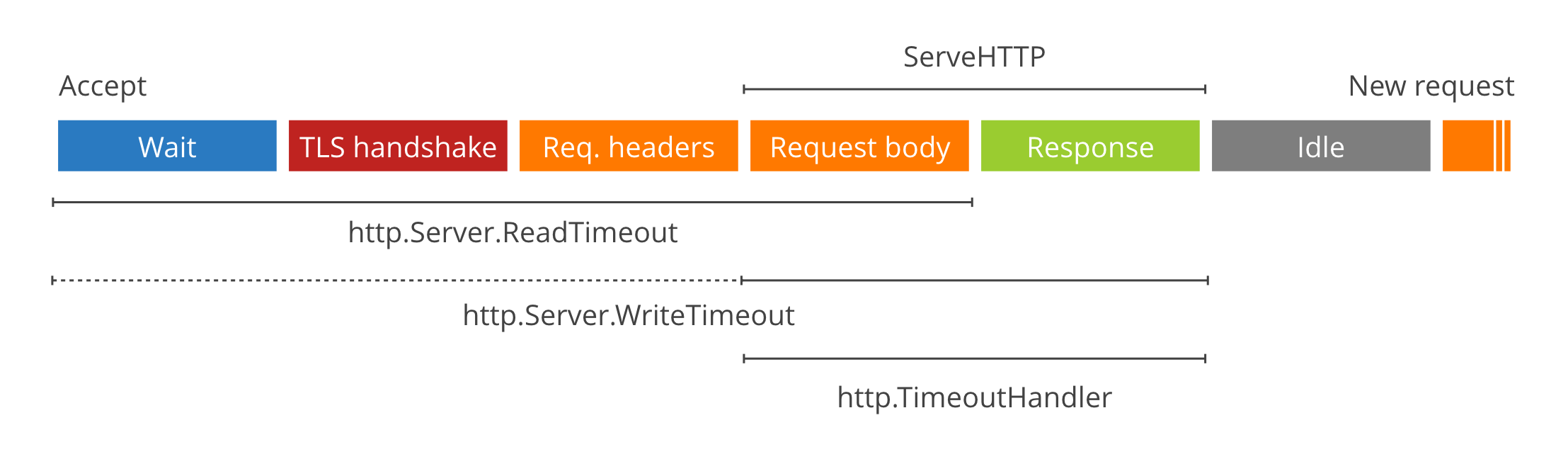
这是一张非常重要的图,因为它展示了 http.Server 处理 HTTP 请求的不同阶段。http.Server 启动后会调用 Accept 方法,等待客户端发起 HTTP 请求。一旦客户端建立 TCP 连接,服务器就开始等待客户端发送 HTTP 请求。这对应最左边的 Wait 阶段。一般 Go HTTP 服务很少直接对外,所以 TLS 会话都会由边缘网关(比如 Nginx)处理,所以我们跳过 TLS handshake 阶段。没有 TLS 会话,http.Server 就开始读取 HTTP 请求的 header 部分,也就转入 Req.headers 阶段。处理完请求的 header 信息,http.Server 就知道应该调用哪个 Handler 的 ServeHTTP 方法,从而进入 ServeHTTP 阶段。服务器在 Req.headers 阶段不会读取请求的 body 内容,而是给 Req 对象准备了一个 Body 对象,ServeHTTP 阶段的业务代码可以根据实际业务决定如何读取 body 内容。所以 ServeHTTP 阶段分成了 Request body 和 Response 阶段。服务器发送 Response 之后就进入 Idle 阶段,等待当前连接的下一个 HTTP 请求。
以上就是 http.Server 处理 HTTP 请求的主要过程。我们回到前面说的超时配置和 TimeoutHandler。
ReadTimeout 控制的是从 Wait 到 Reqeust body 这一段的超时。如果我们把 ReadTimeout 设置成 50ms,那么客户端必须在 50 毫秒内将请求的 header 和 body 都发送给服务器,不然就会超时,服务器会取消整个处理过程。另一方面,HTTP 请求的 header 部分是用 \r\n 分割,并且以一个空行\r\n\r\n表示 header 部分的结束(body 部分的开始)。服务端没法事先确定 header 部分数据的长度,只能一边接收一边解析。这样协议非常方便后续的升级和扩展,但让服务器非常被动。所以有必要为这个过程设置单独的超时时间。该超时由 ReadHeaderTimeout 控制。如果我们设置了 ReaderHeaderTimeout 为 10ms,那么客户端就必须在 10 毫秒内发完全部 header,不能磨磨蹭蹭。如果设置了 ReadTimeout 而没设置 ReadHeaderTimout,http.Server 会用 ReadTimeout 的值设置 ReadHeaderTimeout。
服务器给客户端发送 Response 也需要控制超时。为什么呢?如果客户端的请求处理完成了,但就是不接收 Response 或者故意收的很慢,就会一直占用服务器资源。所以有必要「惩罚」那些慢吞吞和不怀好意的客户端。如果将 WriteTimeout 设成 50ms,那客户端必须在 50 毫秒内接收所有响应数据,不然就取消整个处理过程。有一点注意,WriteTimeout 时间包含了读取 body 的时间。也就是说 ReadTimeout 和 WriteTimeout 的超时在读取 body 这部分是重叠的。
IdleTimeout 控制的是 Idle 阶段的等待时间。如果一次请求结束后好长时间都没有收到新的请求,服务端就会主动关闭当前 TCP 连接,从而释放资源。
最后就是 TimeoutHandler。TimeoutHandler 的使用也非常简便:
handler := ...
handler = http.TimeoutHandler(handler, 1*time.Second, "Timeout!\n"),这样就把一个普通的 handler 变成了一个具有超时控制的 handler。TimeoutHandler 控制的 Reqeust body 和 Response 这两个过程,也就是 ServeHTTP 过程。如果整个过程超过指定的时间(上例中是 1 秒),http.Server 会直接返回 503 并取消整个处理过程。
好了,到现在为止就超时控制的基础知识就介绍完了,下面开始分析具体问题。
问题定位
当年我在写框架的时候觉着这么多 Timeout 配置太复杂,而 TimeoutHandler 貌似可以起到「一夫当关,万夫莫开」的效果,于是决定只用 TimeoutHandler 来控制超时。重点来了,如果其他配置项没有指定,http.Server 默认是不超时,也就是等你到天荒地老。这就为后面的问题埋下隐患。
我们部署的 AWS 上的服务出现部分 Unexpected EOF 报错,经排查发现是客户端行为异常。对应的客户端通过 Content-Length 头指定了 body 的长度,却始终不发送 body 数据。我们预期的结果是触发 TimeoutHandler 超时,并给客户端发送 503 状态码。但实际却是在客户端主动关闭连接后我们的服务报了 Unexpected EOF 错误。
完全不符合预期,必须一查到底!这个场景非常容易复现,所以排查起来比较容易。只要运行如下代码:
package main
import (
"io"
"net/http"
)
func main() {
http.HandleFunc("/ping", func(w http.ResponseWriter, req *http.Request) {
buf, _ := io.ReadAll(req.Body)
w.Write(buf)
})
s := http.Server{ Addr: ":8080" }
s.ListenAndServe()
}使用 telnet 模拟发起如下 HTTP 请求就能复现:
POST /ping HTTP/1.1
Content-Length: 6
Host: localhost:8080
he注意⚠️请求中 Content-Length 的长度为 6,但实际只发送了 he个字节。
最开始我怀疑🤔 TimeoutHandler 可能必须等读到所有 body 数据才能工作,于是看了它的源码:
func (h *timeoutHandler) ServeHTTP(w ResponseWriter, r *Request) {
// 设置 ctx 超时时间
ctx, cancelCtx = context.WithTimeout(r.Context(), h.dt)
defer cancelCtx()
r = r.WithContext(ctx)
done := make(chan struct{})
tw := &timeoutWriter{ w:w, h:make(Header), req: r }
// 新起协程处理 http 主求,当前协程等待结果或者超时
go func() {
// process panic
h.handler.ServeHTTP(tw, r)
close(done)
}()
select {
// case panic
case <-done: // 请求正常处理完成
case <-ctx.Done(): // ctx 超时了
}
}也就说整个 ServeHTTP 过程都是可以控制的。而我们实际也在 ServeHTTP 读取 req.Body 数据。理论上 TimeoutHandler 应该可以起作用。于是我们开启 print 大法,在直接在 TimeoutHandler 源码中插入 Print 语句看到底有没有执行,最终发现是卡在了后面的 select 过程。也就是<-ctx.Done() 这个 case,对应的源码为:
tw.mu.Lock()
defer tw.mu.Unlock()
w.WriteHeader(StatusServiceUnavailable)
io.WriteString(w, h.errorBody())
tw.timedOut = true你可能不信,居然是卡在了 Write 这一步,这确实没有想到!
现在就需要看一下为什么会卡住。w的是一个 ResponseWriter 接口,我们得找到它的具体实现。下面是 http.Server 的serve()方法的核心流程:
func (c *conn) serve(ctx context.Context) {
//...
for {
w, err := c.readRequest(ctx)
// ...
serverHandler{c.server}.ServeHTTP(w, w.req)
// ...
w.finishRequest()
// ...我们可以看到,w是通过调用 c.readRequest(ctx) 构造出来的。根据 readRequest 的接口签名,我们得知w的实际类型是 http.response。进一步查看w的 Write 方法,发现它在底层调用了 w.w 的 Write 方法。w.w 是 http.response 的一个成员,其类型是 *bufio.Writer 接口,所以我们不得再去找它的具体实现。回到前面的 c.readRequest 方法,在函数的最后面有这么一行:
w.w = newBufioWriterSize(&w.cw, bufferBeforeChunkingSize)原来这个 w.w 是通过 w.cw 构建出来的。我们再看 cw 的类型,是 http.chunkWriter,最终找到了 cw.Write 函数,这就是前面卡住的 c.Write 函数,相关代码如下:
func (cw *chunkWriter) Write(p []byte) (n int, err error) {
if !cw.wroteHeader {
cw.writeHeader(p)
}
// ...实际卡在了 cw.writeHeader(p) 这个地方。这个 writeHeader 函数非常复杂,经过一番调试,最终找到这个地方:
func (cw *chunkWriter) writeHeader(p []byte) {
// ...
if w.req.ContentLength != 0 && !w.closeAfterReply {
var discard, tooBig bool
switch bdy := w.req.Body.(type) {
// ...
case *body:
bdy.mu.Lock()
switch {
case bdy.closed:
// ...问题的根源就是这里的 bdy.mu.Lock()!原来 http.Server 在发送 response 需要锁住 request 的 body 对象。这又是图个啥呢?这段条件分支上有一段注释:
// Per RFC 2616, we should consume the request body before
// replying, if the handler hasn't already done so.简单说就是在发送响应之前需要读取所有 request 的 body 内容。整个过程卡在了 bdy.mu.Lock() 这一步,肯定是有协程已经拿到了锁在等什么事情,没有释放锁。查一下使用这把锁的地方,一下子就找到了这里:
func (b *body) Read(p []byte) (n int, err error) {
b.mu.Lock()
defer b.mu.Unlock()
if b.closed {
return 0, ErrBodyReadAfterClose
}
return b.readLocked(p)
}这里的 Read 就是我们在具体的 handler 调用 io.ReadAll(req.Body) 把调用的方法。它首先就会锁住 b.mu.Lock(),等读完所有请求内容的时候才会释放。我们再看看这里的b.readLocked(p):
func (b *body) readLocked(p []byte) (n int, err error) {
if b.sawEOF {
return 0, io.EOF
}
n, err = b.src.Read(p)
// ...这里实际调用了 b.src 的 Read 方法。b.src 又是一个 io.Reader 接口,我们又得想办法找到它的具体实现。这个找起来相对麻烦一点。最终找到的调用链是 c.ReadRequest -> http.readRequest -> http.readTransfer。这个 readTransfer 又是相当的复杂,相关流程如下:
func readTransfer(msg interface{}, r *bufio.Reader) (err error) {
// ...
realLength, err := fixLength(...)
// ...
switch {
case t.Chunked:
// ...
case realLength == 0:
t.Body = NoBody
case realLength > 0:
t.Body = &body{src: io.LimitReader(r, realLength), closing: t.Close}
default:
// ...首先是通过 fixLength 确定 body 的长度。在我们的问题中,body 长度通过 Content-Length 获取,然后命中realLength > 0这个分支。所以 b.src 实际上是一个 io.LimitReader。这个 Reader 会阻塞住,直到读满长度为 realLength 的数据才会返回。
到这里算是定位到问题的根源。原来是客户端发了 Content-Length 头信息,但实际的 body 内容长度不够,所以业务代码在尝试读取全部 body 内容的时候锁住了 bdy.mu,并一直等客户端发送剩余的内容。但客户端一直都没发,最终触发 TimeoutHandler 超时。 TimeoutHandler 尝试给客户端发送 503 响应,但也需要锁住 body,从而也被卡住。整个过程一直持续到客户端主动断开连接,这个时候服务端才会触发一个 Unexpected EOF 报错。从效果上看好像是服务端「死锁」了。
整个排查过程到这里就结束了。下面进行技术总结(ping 王刚):
- http.Server 默认永不超时,所以有被 DDos 攻击的可能
- 只设置 TimeoutHandler 不能应对所有超时场景
- 必须设置 ReadTimeout 和 WriteTimeout,在必要的时候可以设置 ReadHeaderTimeout
还有一个问题就是 http.Server 大量使用接口,阅读代码极不方便。最好的办法就是单步调试。我一直用 vim 开发,对单步调试不太友好,也很少用。后面试了一下 dlv,确实节省了很多时间。
神秘协程
现在补一下番外篇!
在 http.server 方法中有这么一段:
if requestBodyRemains(req.Body) {
registerOnHitEOF(req.Body, w.conn.r.startBackgroundRead)
}字面意思是在 body 读完的时候执行 w.conn.r.startBackgroundRead。对应的执行代码长这样:
func (b *body) readLocked(p []byte) (n int, err error) {
// ...
if b.sawEOF && b.onHitEOF != nil {
b.onHitEOF()
}
// ...进一步看一下这个 startBackgroundRead 函数:
func (cr *connReader) startBackgroundRead() {
// ...
go cr.backgroundRead()
// ...启了一个新协程。也就是说,对于每一个 http 请求,至少会启动两个协程。而这个 backgroundRead 函数也很奇怪,它会试着从底层 TCP 连接读取一个字节,而且会一直阻塞,不受前面的所有超时控制。这个逻辑越看越奇怪🤔必须搞明白。
反复看代码也不得其要领,于是祭出 git blame 大法。为此还专门下载了 go 的源码,最终找到了提交记录1:
net/http: make Server Handler's Request.Context be done on conn errors
This CL changes how the http1 Server reads from the client.
The goal of this change is to make the Request.Context given to Server
Handlers become done when the TCP connection dies (has seen any read
or write error). I didn't finish that for Go 1.7 when Context was
added to http package.其本意是为了在底层 TCP 连接关闭的时候(也就是客户端主动关闭连接)取消当前 handler 的处理过程。一般使用事件回调来处理这种问题最为方便。但是 Go 语言都是协程加同步阻塞的编程范式,没有向应用层暴露事件回调的能力。所以只能是起一个协程尝试读取一点内容(不能是零,那就读取一个字节)。理论上会一直阻塞,直到当前请求处理完毕或者客户端主动断开连接。但就是为了这个特性,却要开一个协程,不得不说是 Go 语言的一个缺陷。
另外,HTTP 协议规定了 pipeline 特性。客户端可以不等服务端响应,而一次性发送多个 http 请求给服务端。然后服务端按顺序发送对应的响应。那 http.Server 为了检测客户端主动断开连接而起的新协程,如果碰到了支持 pipeline 的客户端,就会真的收到一个字节的内容,所以还需要把这一个字节保存下来,供后续处理使用。总之,这种方式不是很优雅。但也只能是目前 Go 语言环境中唯一可行的方案了。大家怎么看呢?😄