默克尔树简介
涛叔默克尔树(Merkle Tree)广泛应用于分布式系统。我最早在学习区块链技术时了解到这一数据结构。但因为几乎没有在工作中用到过,所以对相关的概念和特性一直都似是而非。今天研究浏览器证书透明度日志的时候读到 Cloudflare 的一篇文章1,也讲到默克尔树。文章内容简洁明了,一下子就掌握了该数据结构的特性和要解决的问题。现在结合自己的理解分享给大家。
理解数据结构最简单的办法是从问题出发,而不是从定义出发。就默克尔树而言,它要解决的是如何验证数据的问题。简单来说就是给定一组数据,如何验证其中的部分或者全总数据都是准确的,或者说都没有被篡改。
校验数据完整性最经典的方法是使用内容摘要算法(也叫哈希算法或者杂凑算法)。
比如给定文件内容为”hello, world”,其对应的 MD5 摘要是
e4d7f1b4ed2e42d15898f4b27b019da4这里的关键是根据文件内容计算出一个摘要值。只要文件内容出现任何改动,那么计算出的摘值就会不一样。这就实现了数据校验的效果。那有没有这种情况,就是两个文件内容不同,但计算出来的摘要值却相同呢?实际这种情况也是可能出现的,只是出现的概率很低,人们通常假设不会冲突。如果能出现,那是否可以人为生成文件内容,使它的摘要值等于某个固定值呢?其实也是可以的。同样因为概率极低,人们通常认为这是「不可能」发生的。所以摘要函数通常也叫作单向函数。就是你可以通过内容计算摘要值,很难反过来通过摘要值生成内容。但随着数学研究的发展以及硬件速度的提高,让计算机生成指定摘要值的内容的概率大为提高。单向函数也不再单向了😂所以业界已经开始淘汰诸如 MD5/SHA1 这一类的弱强度摘要算法,很多时候需要使用 SHA256 甚至 SHA512 等高强度算法。但无论如何,哈希碰撞总是有可能发生的。
以上是对单个文件进行校验。回到开始的问题,如何对多个文件做校验呢?最暴力的办法是把所有文件的内容连接起来一并计算摘要值。简单粗暴,也确实有效。只不过每次校验都需要把所有的文件内容都算一遍,是不是有点太浪费了呢?如果我们已经明确怀疑只有其中少部分文件可能有损坏,有没有办法只校验其中的这一部分文件呢?
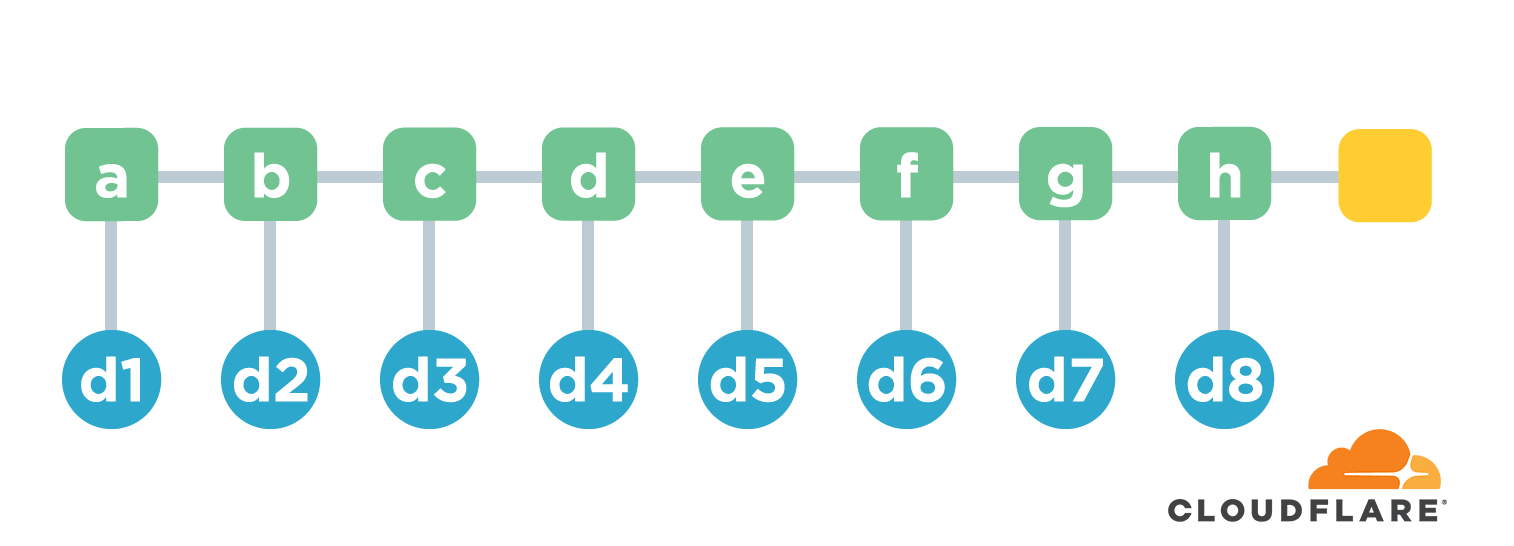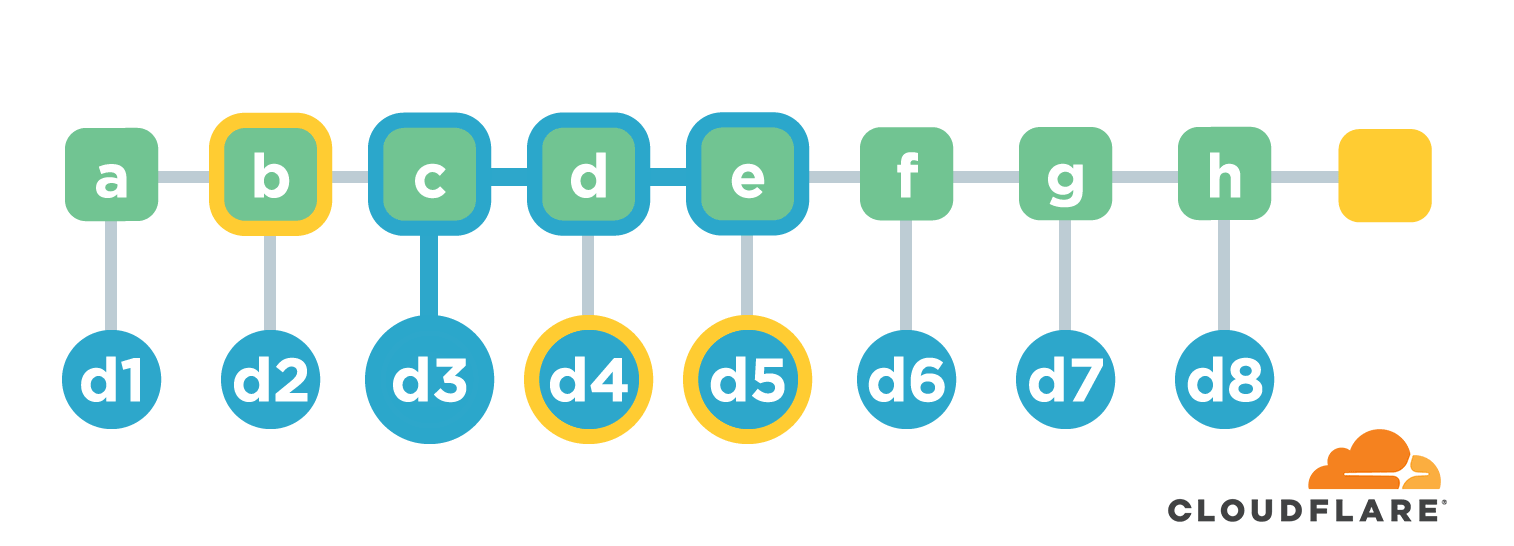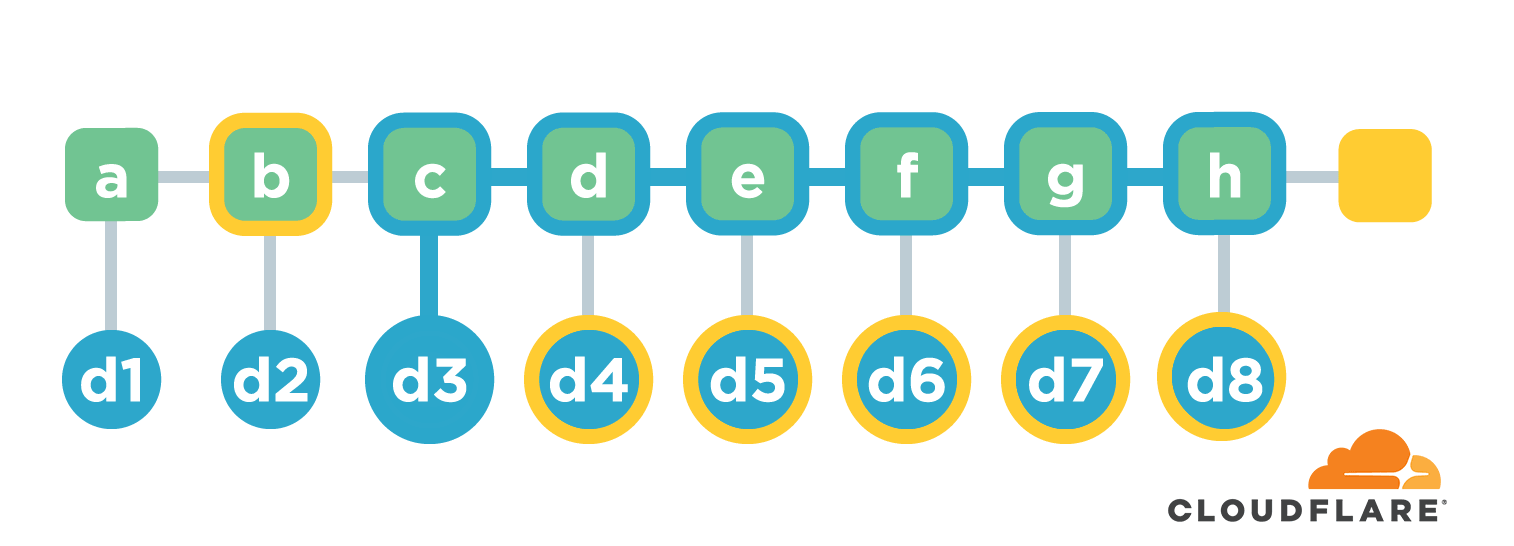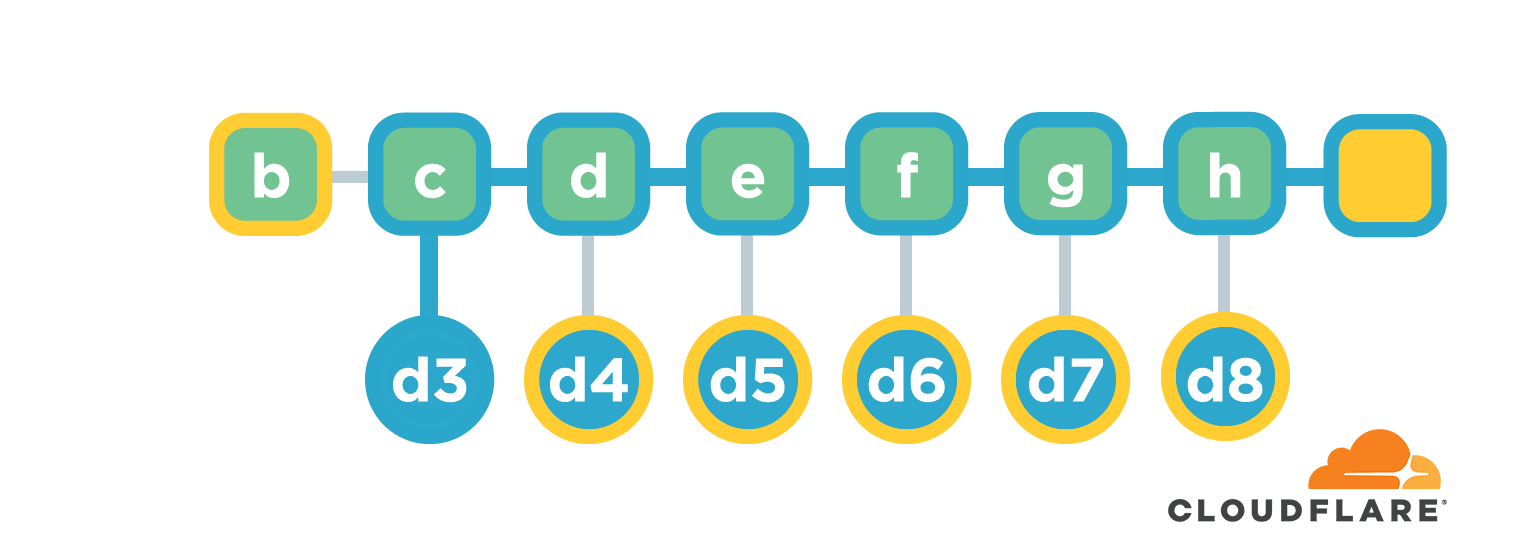
这就需要用到一种链式结构了。链式结构是我自己发明的叫法😄简单来说就是将多个文件按照某种顺序排列好。先计算第一个文件的摘要值。从第二个文件开始,计算不光要计算文件本身的摘要值,还要把文件的摘要值跟前一个文章的摘要值连接起来再计算一个摘要值,以此作为该文章的摘要值。

以上图为例,我们有a-h共8个文件。第一个文件的摘要值为d1=hash(a)。从第二个文件的摘要值为d2=hash(hash(b).d1)。这里的.表示连接两个字符串。以此类推,最终得到一个摘要值为d9=hash(h).d8,用它表示这8个文件共同的摘要值。如果任意文件的内容有损坏或者被篡改,计算出来的摘要值都会发生变化。嗯,功能实现了。
链接结构在生成摘要值的时候很高效,而且每次添加新文件的时候只需要根据原来的总摘要值和新文件的摘要值就能计算新的总摘要值。但是这种结构在校验文件内容的时候就比较低效了。比如我们想校验 d3 是否准确则需要知道文件b-d的全部内容并重新计算摘要值,然后跟最终的摘要值对比。如果文件内容比较多,这个过程会非常耗时。
一般的内容校验大多是读多写少。基本都是一次性生成,但可能需要在不同的地方反复校验。所以我们需要一种对校验过程更简便也更高效的数据结构。这就是本文要说的默克尔树!
要把O(N)的问题转化为O(log2(N))的问题,基本上都要用到二叉树或者二分法。默克尔树就是一种二叉树。文件排好序后先计算每个文件的摘要值,这一组称为叶节点。然后每两个摘要值为一组,连接后再计算摘要值。将计算后的结果再两两分组,连接后计算。以此类推,直到算出唯一的摘要值,用它来表示所有文件的整体摘要值。下图中绿色节点的字母表示各层计算的摘要值,是为了方便引用,不要跟前面的文件名a-h混淆。默克尔树中也只保存摘要值。
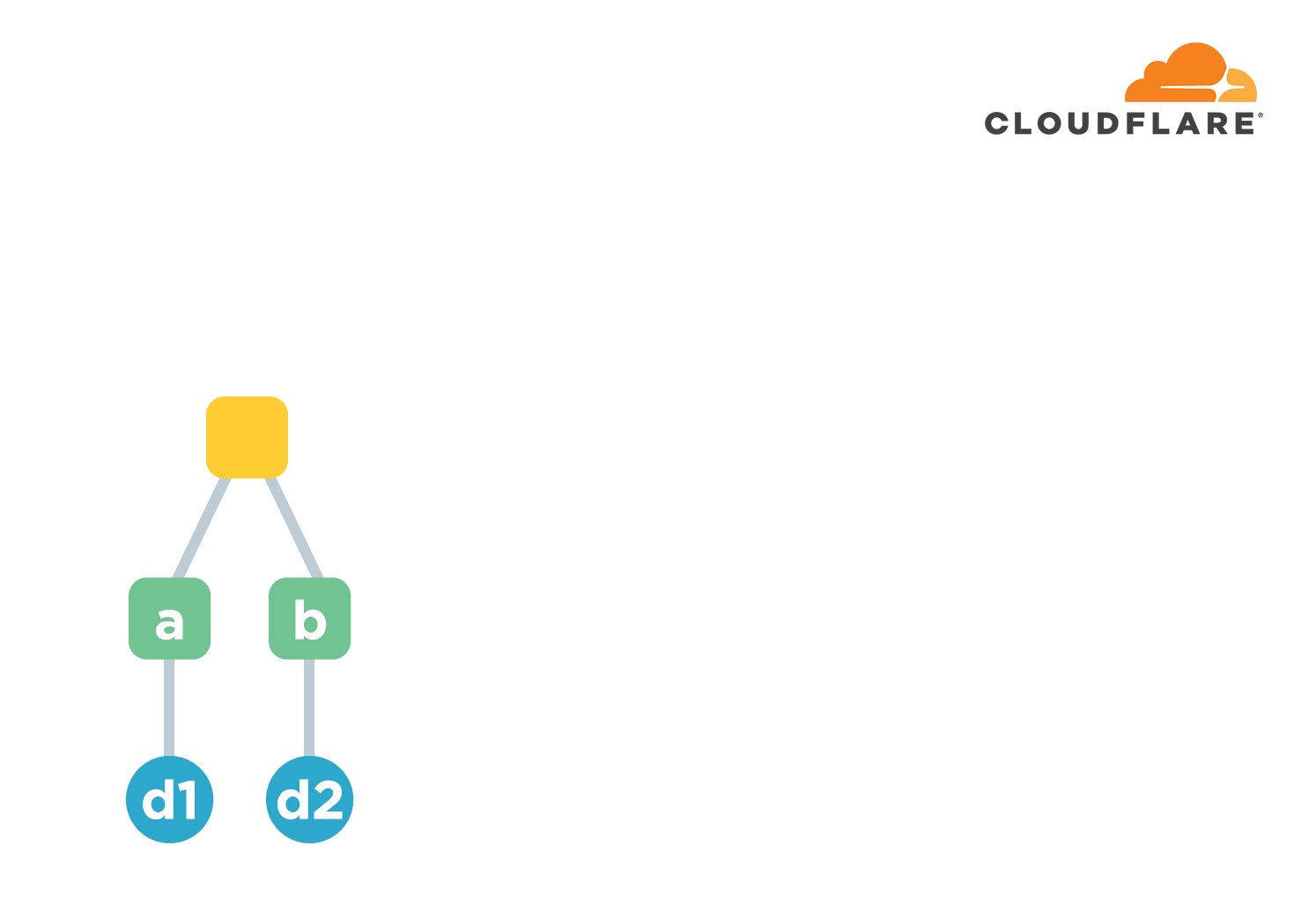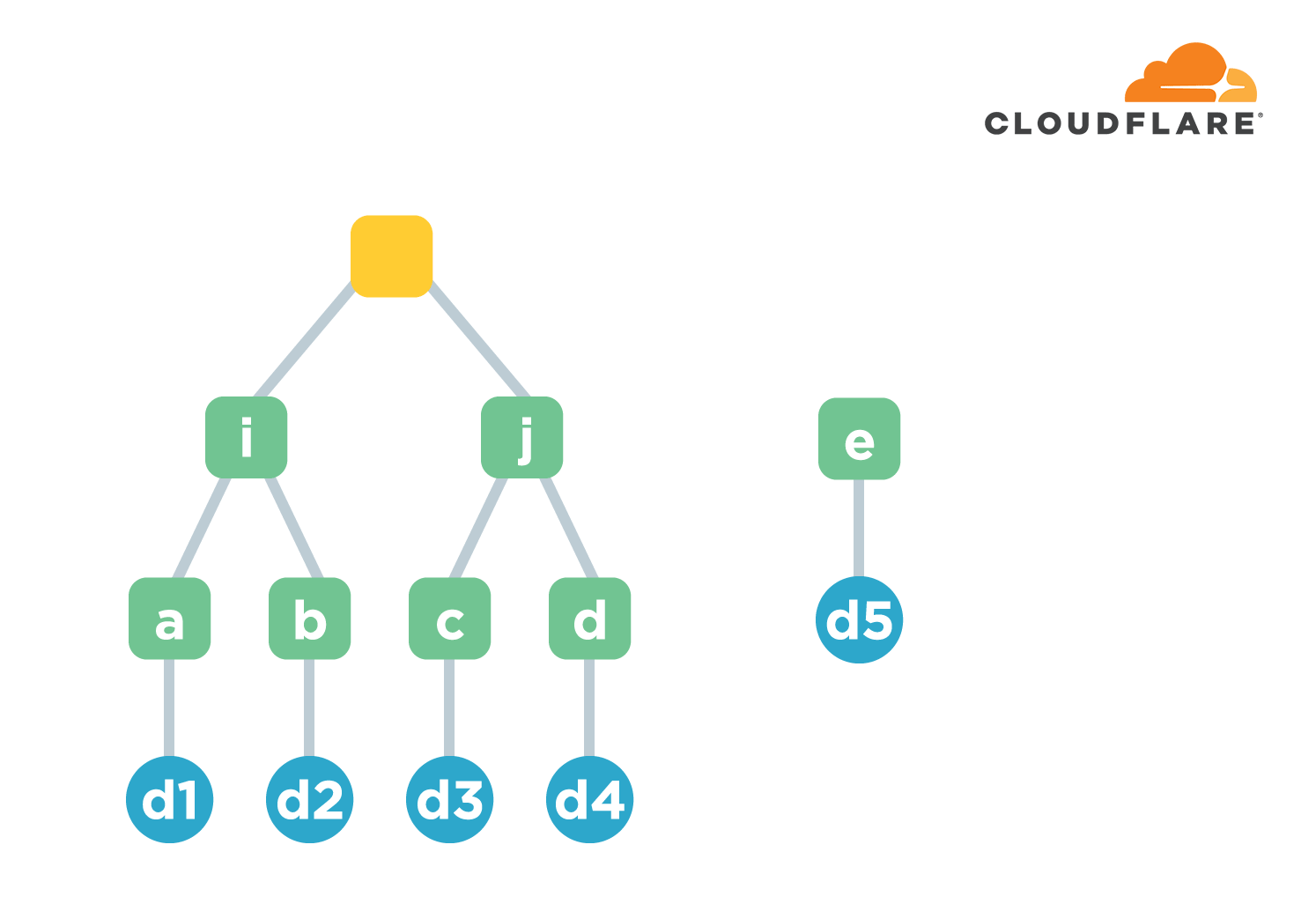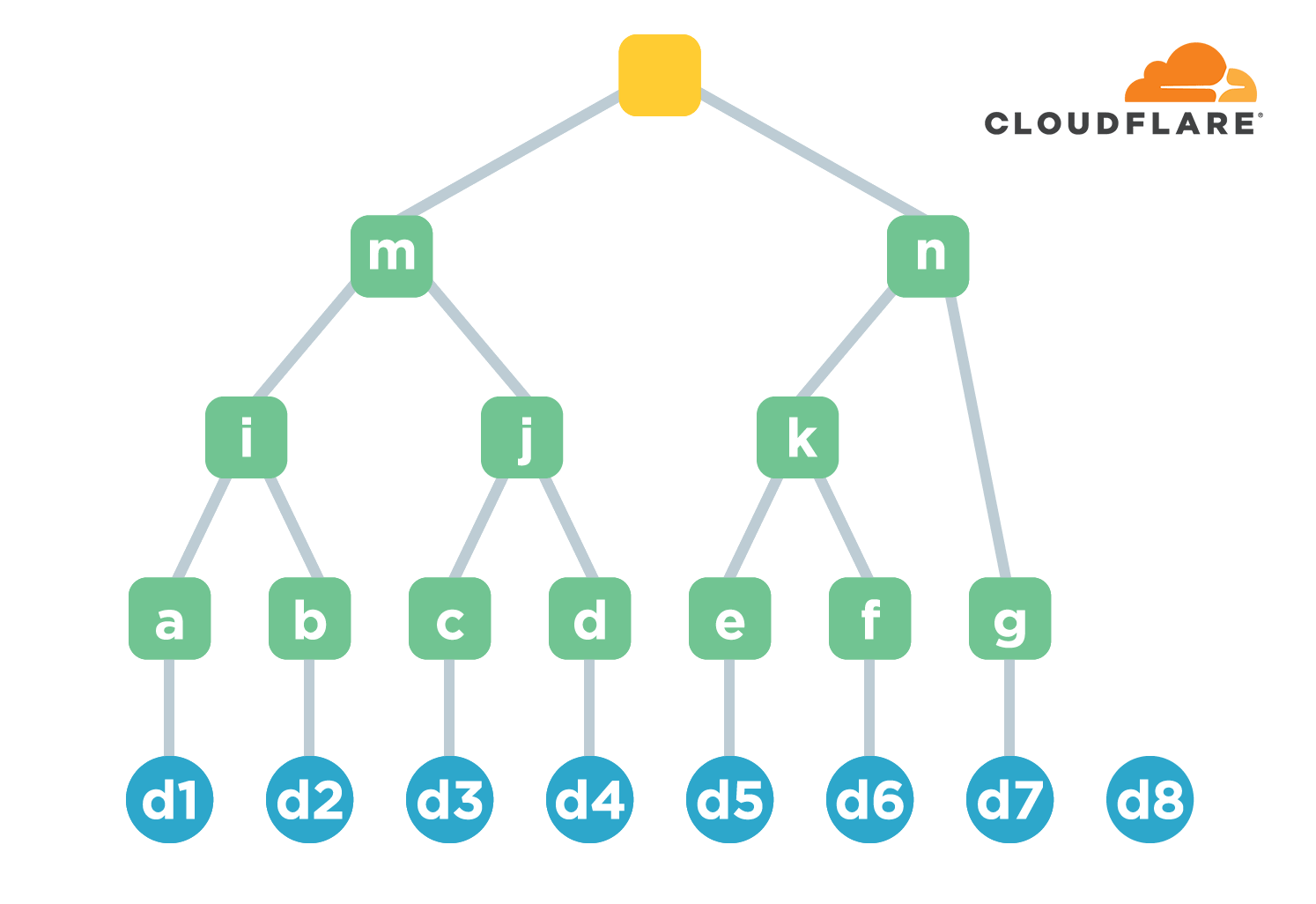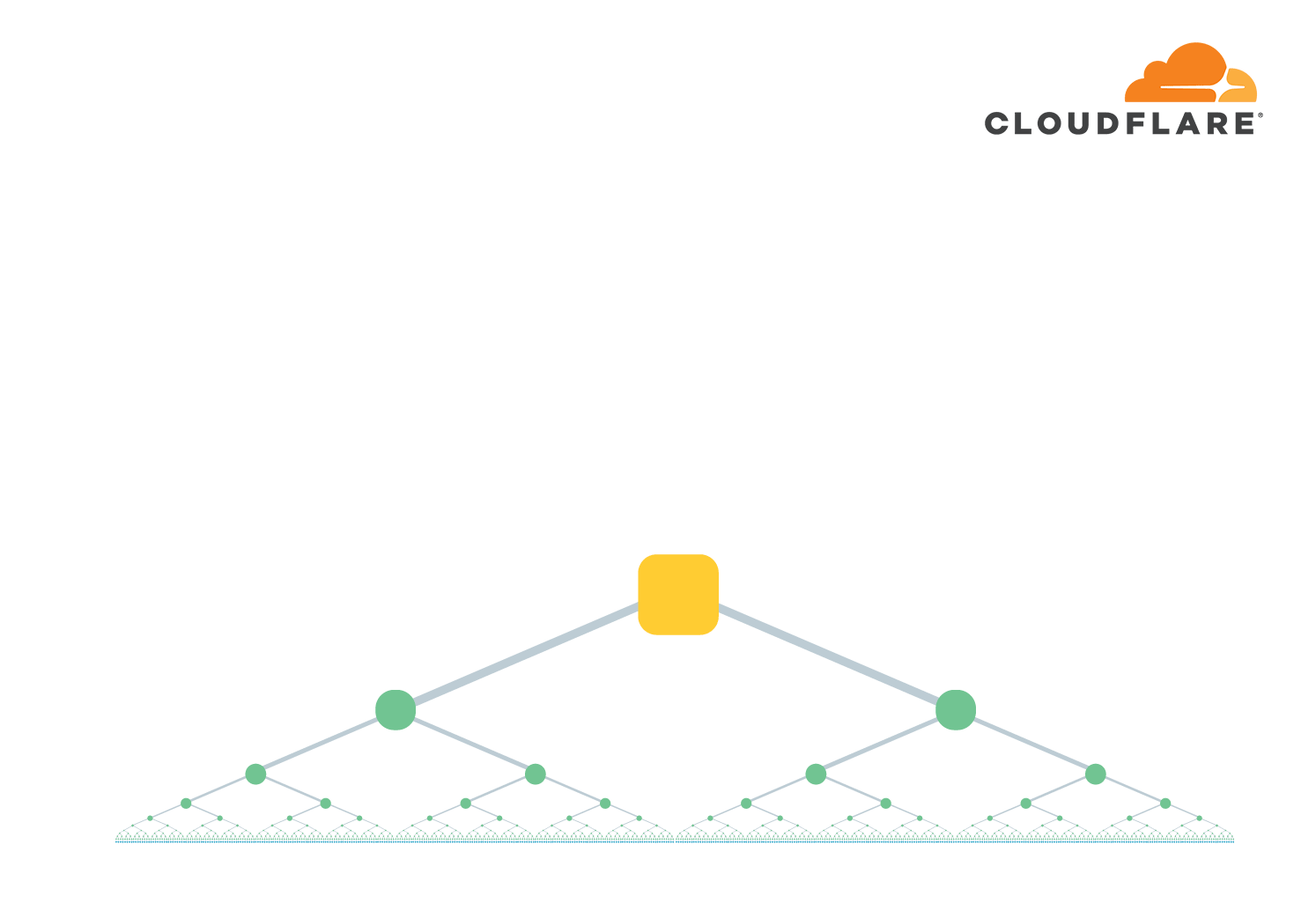
显然,如果文件数量为N,那么树的高度基本是log2(N)。添加新文件时需要计算摘要的最大次数就是树的高度,效率比前面的链式结构要差(因为是常数)。但默克尔树的校验效率则大为改善。
还是以校验 d3 为例。首先确认从 d3 到根节点的路径,也叫 co-path。然后找到路径上每个节点的直接子节点,也就是 i/d/n 这三个,然后就能计算根节点摘要值。拿计算后的摘要值跟原来的作比较就能确定 d3 是否有效,也就是对应文件 c 内容是否有损坏。
以上就是默克尔树的主要内容。在实际使用的时候,有些细节需要处理。比如在有些实现中如果叶节点的数量不是偶数,则会让最后一个节点重复一次,也就是自己跟自己做联合摘要。但这些处理不会对默克尔树的性质产生根本性影响。
默克尔树在分布式系统中有很多应用。最著名的莫过于比特币的区域链。比特币的所有交易都被分散保存在不同的区块里。而在某一个区块中,所有的交易数据的摘要值会被组织成默克尔树,然后保存到区块中。客户端可以很方便地校验某笔交易是否有效!但使用最广泛的例子可能就是 Git 了😄这点大家可能想不到。在 Git 里,每个文件都会根据内容生成 SHA1 摘要值,然后根据目录结构生成一颗默克尔树,对应的数据会最终保存到提交记录里。但无论是区域链还是 Git,它们在使用默克尔树的同时还使用了前面说的链式结构。区块与区块之间,提交与提交之间都是以链式结构连接。也正因此,某交易一旦保存到区块或者某文件一旦提交到 Git,后面就很难改动了。因为局部的改动会导致在它之后的所有区块或者提交记录都失效。在 Git 中可以使用 rebase 等手段实现,但区域链中则几乎不可能。
也正因为默克尔树是一种可以验证的数据结构,业界还用它保存 HTTPS 证书的签发记录。 CA 厂商每签发一张证书就需要向某基于默克尔树的证书透明度日志系统写一条日志。一旦提交即无法更改。浏览器在创建加密连接时查询这些日志来判断是否有厂商错误签发了证书。因此也就有了本篇文章😝