Prometheus 简介
涛叔我最近的工作重心转到 SRE 领域,当前的主要内容是帮助部门完善监控系统。说起监控,大多数做 SRE 的朋友都会想到 Prometheus,中文译名是普罗米修斯。我很早就知道、平时也大量使用。但因为之前主要做开发工作,一直没有仔细研究它:基础概念比较模糊,查询语法一知半解,采集、存储等方面则完全不懂。这次就梳理一下最近学到的内容,希望能给新入门的朋友提供一些参考。
先贴一张官方的架构图

图的左边是监控对象和数据采集,右边是图表展示和告警,中间的 Prometheus 是把左右结合起来的纽带。基于这张架构图,我把本文的内容分成采集、查询、使用三个部分。又因为监控指标本身也比较复杂,我们单独设置概念一节加以说明。所以本文总共有四个部分。现在开始逐一介绍。
基础概念
监控指标英文对 metric,它包罗万象、五花八门。像 CPU 负载、系统进程数量、TCP 连接数量、网络流量、HTTP 服务每秒请求数、请求平均耗时,甚至还有 HTTP 接口请求的 99 分位数,这些都是监控指标。虽然它们含义不同,形式不同,单位也不一样,但它们却有一个共同点,都是随时间变化。也就是说它们都是一组时间序列,或者也可以说是时间的函数。理论上,在理想的监控系统里,给定一个时间点,我们就能查出对应的指标值。但现实中肯定做不到,我们需要对指标做采样。也就是每隔一段时间查一下对应的指标值并保存下来。
时间序列是监控指标的共性。但不同的指标也有自己的个性。比如系统进程数量,它的取值随时间变化可大可小,我们主要关心它当前的取值,如果太大就会有问题。但网络流量就不太一样了,因为它的值会一直增长,不可能缩小,除了关心当前的网络传输总量,我们还希望了解数据传输的速度。像接口耗时 99 分位数则更加复杂,这需要采集大量的数据并做统计才得得取具体数字。
指标结构
每个指标包含一组随时间变化的样本数据,以及与之关联的一组标签。结构如下:
[[t1,v1],...,[tN,vN]] -> {lab1:l1,lab2:l2,lab3:l3}Prometheus 内部定义了特殊标签__name__来表示同一类指标的名字。比如 HTTP 请求数指标可以定义为http_requests_total。指标名需要满足正则表达式[a-zA-Z_:][a-zA-Z0-9_:]*,简单说就是可以包含大小字母、数字、下划线、冒号,但不能以数字开头。
一种指标可以有一个或者多个标签,来表示不同的指标维度。还是以 HTTP 请求为例,我们可以定义status指标来统计接口不同状态码的数量,比如 2xx 请求数可以是
http_requests_total{status="2xx"} 100 1395066363000后面的数字100表示指标当前的取值,再后面是毫秒时间戳,表示采样时间点。不过一般不需要输出,如果没有 Prometheus 会使用当前时间作为样本时间点。
本节剩余部分为方便排版,统一省略指标取值和时间戳。
与此同时我们还可以再定义handler标签来区分不同的接口,比如:
http_requests_total{status="2xx",handler="/login"}
http_requests_total{status="5xx",handler="/home"}标签的取值范围跟名字类似,但不允许使用冒号。另外,双下划线__开头的指标留作 Prometheus 内部使用,我们平时不要定义这样的指标。
有的朋友会把指标相象成数据库的表,把标签看成是表的字段。虽然很形象,但并不准确。在 Prometheus 中只有时间序列一种数据。所有的指标加上不同标签的组合计算笛卡尔积,每一种组合对应一组时间序列数据。其实在 Prometheus 内部,指标名本身也是一种标签,它对应__name__。假设我们有两个接口/login和/home,对应五类状态码,那么实际会存储十组时间序列数据:
http_requests_total{status="1xx",handler="/login"}
http_requests_total{status="2xx",handler="/login"}
http_requests_total{status="3xx",handler="/login"}
http_requests_total{status="4xx",handler="/login"}
http_requests_total{status="5xx",handler="/login"}
http_requests_total{status="1xx",handler="/home"}
http_requests_total{status="2xx",handler="/home"}
http_requests_total{status="3xx",handler="/home"}
http_requests_total{status="4xx",handler="/home"}
http_requests_total{status="5xx",handler="/home"}如果你是 RSET 接口的拥趸,喜欢把 ID 加到 URL 路径里,那么 Prometheus 的时间序列数据就会爆炸:
http_requests_total{status="2xx",handler="/user/1"}
http_requests_total{status="2xx",handler="/user/2"}
http_requests_total{status="2xx",handler="/user/3"}
...所以一定要注意控制指标的数量。
以上是介绍了指标的命名和结构。为了能支持尽可能多的监控指标,Prometheus 还定义了四种类型,它们分别是 Count/Gauge/Histogram/Summary。
Counter
Counter 类型的指标随时间单调递增,只会增大不会减小。最典型的就是接口的请求次数、网络传输的流量等。对于 Counter 类型的指标,Prometheus 可以根据时段计算出该指标的速率。假设我们采集了请求次数指标,类型为 Counter,那们我们同时也能计算出接口的 QPS 指标。这部分我们会在查询一节详细说明。
Gauge
并非所有的指标都能使用 Counter 表示。像是温度、系统可用内存、CPU 负载等,它们的取值随时间可大可小,所以需要一种新的指标类型,这就是 Gauge。
理论上所有的指标都能用 Gauge 表示,但前提是我们需要提前计算好。比如接口的 QPS 指标,我们完全可以根据时间自行算出来,再用 Gauge 类型来表示。但这类的计算过程都可以复用,也就是可以由 Prometheus 统一完成,没必要由程序自己算。所以说能用 Counter 类型尽量不用 Gauge 类型。
除了 Counter 和 Gauge,Prometheus 还支持一类更复杂的类型 Histogram 和 Summary,它们主要用来计算类诸如接口耗时 99 分位数之类的统计指标。
Histogram
一种 Histogram 指标其实是一组指标的集合。以接口耗时为例,我们需要先给时长分段。假设时间单位是秒,我们的分割点是:
.005, .01, .025, .05, .1, .25, .5, 1也就是说分别是 5ms、10ms、25ms、50ms、100ms、250ms、500ms、1s。
假设接口耗时指标名为 http_request_duration_seconds,那么对于 Histogram 类型,我们要依次统计如下 Counter 指标:
http_request_duration_seconds_bucket{le="0.005"}
http_request_duration_seconds_bucket{le="0.01"}
http_request_duration_seconds_bucket{le="0.025"}
http_request_duration_seconds_bucket{le="0.05"}
http_request_duration_seconds_bucket{le="0.1"}
http_request_duration_seconds_bucket{le="0.25"}
http_request_duration_seconds_bucket{le="0.5"}
http_request_duration_seconds_bucket{le="1"}
http_request_duration_seconds_bucket{le="+Inf"}
http_request_duration_seconds_count
http_request_duration_seconds_sum假设某请求的耗时为0.03s,那么就需要给le值为0.005/0.01/0.025这三个指标加一,因为它们都比0.03小。另外还需要给_count指标加一,它表示请求总数。最后还得给_sum指标加上0.03,它表示所有请求的耗时总和。
如果某请求的耗时为0.5s,那么需要给le <= 0.5 的所有_bucket指标加一,同时更新 _count 和 _sum 指标。如果耗时超过了一秒,就得给le="+Inf"的_bucket加一。
分多少段,每个分界点的位置并不是定死的,可以由开发者根据情况自行选择。但有一点很明确,精度越高,分段越多,对应的指标也就越多。一般开发者应该预估指标的取值。如果耗时主要分布了 100ms 左右,那么 0-300ms 区间可以多分几段,300ms 以上的可以少分几段。
除了分段,我们也可以给 Histogram 指标组添加其他表签,比如 handler 来表示接口路径,这样上面的指标组会变成:
http_request_duration_seconds_bucket{handler="/login" le="0.005"}
http_request_duration_seconds_bucket{handler="/login" le="0.01"}
http_request_duration_seconds_bucket{handler="/login" le="0.025"}
http_request_duration_seconds_bucket{handler="/login" le="0.05"}
http_request_duration_seconds_bucket{handler="/login" le="0.1"}
http_request_duration_seconds_bucket{handler="/login" le="0.25"}
http_request_duration_seconds_bucket{handler="/login" le="0.5"}
http_request_duration_seconds_bucket{handler="/login" le="1"}
http_request_duration_seconds_bucket{handler="/login" le="+Inf"}
http_request_duration_seconds_count{handler="/login"}
http_request_duration_seconds_sum{handler="/login"}从原理上看,Histogram 指标是在统计取值落入不同区间的频次,有点像中学时所学的频数分布直方图。也正因为是计录了频率分布,所以在能计算分位数信息。具体的计算方法会在查询一节说明。
Summary
Summary 指标可以看成是一类特殊的 Histogram 指标,但它的 le 取值只能是[0-1],标签名也换成了quantile,而且指标名也不需要加上_bucket后缀。
rpc_duration_seconds{quantile="0.05"} 3272另外,如果说 Histogram 指标是统计了频数分布,那么 Summary 统计的就是频率分布。也就是说,客户端如果要曝露 Summary 指标,它必须自己统计指标取值落入不同分位数的数量。
比如下面的 Summary
rpc_duration_seconds{quantile="0.01"} 3102
rpc_duration_seconds{quantile="0.05"} 3272
rpc_duration_seconds{quantile="0.5"} 4773
rpc_duration_seconds{quantile="0.9"} 9001
rpc_duration_seconds{quantile="0.99"} 76656
rpc_duration_seconds_sum 1.7560473e+07
rpc_duration_seconds_count 2693不过说起来怎么计算 Summary 我还没搞明白,等后续弄清楚之后再补上。
到这里我们这介绍完 Prometheus 指标的结构、类型和用途等基本概念。下面继续说如何采集存储。
采集与存储
如果想让 Prometheus 采集指标,程序需要对外提供一个特殊的 HTTP 接口。通常这个接口的路径是/metrics。然后程序需要调用 Prometheus 提供的 SDK 来定义并维护各类指标。
指标编码
因为篇幅原因,本文在此不展开讲如何使用 SDK。但大家需要了解/metrics接口返回的结果。此接口需要返回纯文本内容,编码为 UTF-8,Content-Type 约定是text/plain; version=0.0.4。内容如下:
# HELP http_requests_total HTTP 请求总数
# TYPE http_requests_total counter
http_requests_total{method="post",code="200"} 1027 1395066363000
http_requests_total{method="post",code="400"} 3 1395066363000
# 标签内容需要转义
# 不指定 TYPE 默认是 untyped 类型,不推荐
msdos_file_access_time_seconds{path="C:\\DIR\\FILE.TXT",error="Cannot find file:\n\"FILE.TXT\""} 1.458255915e9
# 最小指标结构
metric_without_timestamp_and_labels 12.47
# 错误指标,时间戳有问题
something_weird{problem="division by zero"} +Inf -3982045
# Histogram 指标,结构很复杂
# HELP http_request_duration_seconds A histogram of the request duration.
# TYPE http_request_duration_seconds histogram
http_request_duration_seconds_bucket{le="0.05"} 24054
http_request_duration_seconds_bucket{le="0.1"} 33444
http_request_duration_seconds_bucket{le="0.2"} 100392
http_request_duration_seconds_bucket{le="0.5"} 129389
http_request_duration_seconds_bucket{le="1"} 133988
http_request_duration_seconds_bucket{le="+Inf"} 144320
http_request_duration_seconds_sum 53423
http_request_duration_seconds_count 144320
# 最后是 Summary 指标,跟 Histogram 类似
# HELP rpc_duration_seconds A summary of the RPC duration in seconds.
# TYPE rpc_duration_seconds summary
rpc_duration_seconds{quantile="0.01"} 3102
rpc_duration_seconds{quantile="0.05"} 3272
rpc_duration_seconds{quantile="0.5"} 4773
rpc_duration_seconds{quantile="0.9"} 9001
rpc_duration_seconds{quantile="0.99"} 76656
rpc_duration_seconds_sum 1.7560473e+07
rpc_duration_seconds_count 2693每种指标都需要添加注释说明。注释以#开头,可多可少。但一般会有两行是以 HELP 和 TYPE 开关的。HELP 后面接指标名,再后面跟着指标的用途;TYPE 后面跟指标名,然后是指标的类型。其他注释就随便了,但一般也就 HELP 和 TYPE 两行。如果没有指定类型,则会被判定为untyped,但不推荐这种做法。
Exporter
如果程序本身不支持通过 HTTP 导出指标,那就得用到所谓的 exporter。拿 Linux 系统为例,显然内核不可能自己监听某个端口,提供当前系统状态监控指标。这就需要用到 node_exporter。 node_exporter 是一个特殊的程序,运行后会主动采集系统负载、TCP 连接数等各类状态指标,然后通过 /metrics 曝露给 Prometheus 来集。同样的 mysqld_exporter 会把 MySQL 的状态转换成 Prometheus 指标,redis_exporter 会把 redis 的状态转换成 Prometheus 指标。基本上常用的组件如果不是原生支持 Prometheus 的话,大概率也会有对应的 exporter,具体可以查看官方整理的列表1。
一般来说,一个服务会对应一个 exporter。比如一台 Linux 主机上需要运行一个 node_exporter;一台 MySQL 机器上需要运行一个 mysqld_exporter。exporter 和被采集对象是一一对应的关系。但在有些场景,我们没办法在实例机器上独立运行 exporter。比如说我们使用云厂商提供的 MySQL 实例,不可能在实例对应的机器上运行 mysqld_exporter。而且我们可能使用多组 MySQL 实例,也没有必要为每一个实例设置一个 exporter。这个时候我们就需要使用所谓的 multi-target exporter。
Multi-target exporter 简单来说就是支持通过传参来确定要采集哪个实例的指标信息。 Prometheus 可以通过访问/probe?target=foo:3306指定要采集foo:3306实例的信息;也可以通过访问/probe?target=bar:3306来集bar:3306的信息。一般来说,普通的 exporter 使用/metrics接口,多目标 exporter 使用/probe,以示区分。但 Prometheus 支持配置,用什么接口区别不大。
单目标配置
以上只能说是支持以 Prometheus 格式来发布指标信息。但要想 Prometheus 定时来采集,还需要给它添加配置。
最简单的配置长这个样:
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['localhost:9090']global中的scrape_interval表示采集间隔,本例中是每15秒采一次。频率越高,精度越高,存储和查询成本也就越高。一般15秒也就够用了,再高也没多大意义。
evaluation_interval 表示计算间隔。Prometheus 采集数据之后还可以根据指定的规则将数据汇总,形成新的指标数据,借此减少查询时的计算消耗。这部分算是高级内容,本文不展弄讨论。另外,Prometheus 还支持告警功能,这个指标也用作检查是否需要报警的时间间隔。
scrape_configs 部分对应的就是一系列的采集任务。每个采集任务都有自己名字和自己的采集列表。上例中的采集列表是固定写死的。如果你用上面的配置启动 Prometheus
prometheus --config.file=prometheus.yml那么 Prometheus 每隔 15s 会自动访问 localhost:9090/metrics 采集监控数据。
多目标配置
如果是要采集 multi-target exporter 则需要费一番周折。先给出配置,再解释原理:
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['localhost:9090']
- job_name: mysql
metrics_path: /probe
static_configs:
- targets: [ foo:3306, bar:3306 ]
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: localhost:3306这里的 mysql 采集任务通过metrics_path指定接口路径,依然使用static_configs 设置采集目标。但是直正的 exporter 却在监听localhost:3306地址。如果没有relabel_configs 配置,mysql 采集任务会依次访问http://foo:3306/probe和http://bar:3306/probe。但我们希望它访问的是http://localhost:3306/probe?target=foo:3306和http://localhost:3306/probe?target=bar:3306。上面的relabel_configs就是为了解决这个问题。
首先,Prometheus 内部会使用__address__保存采集目标的的地址,这里分别对应foo:3306 和bar:3306。我们通过 relabel 将__address__的值写入另一个特殊的标签__param_target。这是一个虚拟标签,它的作用在请求 HTTP 接口时添加额外的参数。因为这里的是__param_{target},所以采集的 URL 会变成 http://foo:3306/probe?target=foo:3306。另一个不重复写了。显然这也不是我们想要的地址。现在的采集地址是foo:3306,如果能正常采集,Prometheus 会在采到的指标上自动添加instance标签,取值为foo:3306。显然我们需要保留这个值。如果我们什么都不做,直接想办法改掉步标地址,那么采集的样本的instance标签就会保存修改后的值。所以这里直接使用 relabel 将foo:3306强制写入instance标签。最后将localhost:3306写入__address__标签,这一步是将采集 URL 变成http://localhost:3306?target=foo:3306。如此一番黑科技,Prometheus 就能从 multi-target exporter 上正确采集指标样本。
这里再讲一下采集任务自动生成的标签。对于采集到的每一个指标,Prometheus 会自动添加 job 和 instance 两个标签,分别对应抓取配置中的 job 名字和采集 target。除此之外, Prometheus 还会自动添加以下指标:
up{job="<job-name>", instance="<instance-id>"}。1表示可以正常抓取。如果不能采集,此指标就会变成0。我们可以通过该指标监控 Prometheus 是否能正常采集数据。scrape_duration_seconds{job="<job-name>", instance="<instance-id>"}记录针对特定采集对象抓取时间。如果某服务有问题或者返回了巨量的指标数据,抓取时间就会变长。scrape_samples_post_metric_relabeling{job="<job-name>", instance="<instance-id>"}记录 relabel 标签数量。原则上不应该有太多 relabel,如果有则需要进一步验证。scrape_samples_scraped{job="<job-name>", instance="<instance-id>"}被抓取的指标数量。scrape_series_added{job="<job-name>", instance="<instance-id>"}针对当前采集对象本次采集新添加的指标序列数量。不是很了解作用,后面补充。
我们可以通过up指标来监控被采集实例是否正常。
自动发现
我们在实际生产环境中需要监控大量的设备和服务。上面这种硬编码的方式显然不科学,我们需要一种让 Prometheus 自动发现采集对象的机制。
最简单的一种是基于文件来发现。我们可用通过程序生成 json 或者 yaml 文件,里面存有采集对象列表。然后通过file_sd_configs指定列表路径。Prometheus 会自动加载文件的内容,还会监听文件的变化并实时更新。采集配置如下:
scrape_configs:
- job_name: 'node'
file_sd_configs:
- files:
- 'targets.json'targets.json 的内容结构如下:
[
{
"labels": {
"job": "node"
},
"targets": [
"localhost:9100"
]
}
]列表文件也可以使用 yaml 格式:
- targes:
- localhost:9100
labels:
job: node在大型系统中可能会有多组 Prometheus 实例。在不同实例上统护采集对象列表可能不方便, Prometheus 还支持各类远程发现机制。最简单的当属http_sd_config,对应的配置如下:
scrape_configs:
- job_name: 'node'
http_sd_configs:
url: "http://foo/targets.json"
refresh_interval: 10s这里最核心的配置项是url,指定了一个 HTTP 链接。因为不能实时感知远端内容的变化, Prometheus 只能定时轮询该链接,以获取最新的采集对象列表。我们可以通过refresh_interval 来设置轮询间隔,默设是一分钟一次。
http_sd_configs 还支持各类认证方式,在此不展开讨论,大家可以参考官方文档。
上面只是两种最简单也最常用的发现方式。Prometheus 还支持很多发现协议,具体大家可以在官网配置文档上搜sd_config,基本上应有尽有了。
Pushgateway
细心的同学可能会发现,无论是单目标采集还是多目标采集,它们都需要被采集对象(系统、应用程序或者 exporter)长期运行。这对一般的服务没有问题。但在实际业务场景中,也有不少系统会不断启动、执行,然后再退出,最典型的就是定时任务。对于这类服务,显然不能使用前面的办法来采集指标。
为了解决这类问题,Prometheus 官方提供 Pushgateway2 组件。Pushgateway 可以看成是一个特殊的 exporter,对外提供 HTTP 接口。但它跟 exporter 又有所不同。exporter 会根据 Prometheus 传入的参数主动查询被采集对象的各类状态,被采集对象通常不会输出标准的 Prometheus 指标,需要 exporter 在中单做转换。而 Pushgateway 则是纯被动等待被采集对象主动上报,被采集对象上报的也是 Prometheus 格式指标。Pushgateway 只是临时保存,不做转换,也不做聚合,然后等 Prometheus 来定时抓取。这样就解决了非常驻型对象的采集问题。
数据存储
Prometheus 使用 TSDB 格式3保存样本数据。默设数据会存储到当前的 data 文件夹,目录结构如下:
./data
├── 01BKGV7JBM69T2G1BGBGM6KB12
│ └── meta.json
├── 01BKGTZQ1SYQJTR4PB43C8PD98
│ ├── chunks
│ │ └── 000001
│ ├── tombstones
│ ├── index
│ └── meta.json
├── 01BKGTZQ1HHWHV8FBJXW1Y3W0K
│ └── meta.json
├── 01BKGV7JC0RY8A6MACW02A2PJD
│ ├── chunks
│ │ └── 000001
│ ├── tombstones
│ ├── index
│ └── meta.json
├── chunks_head
│ └── 000001
└── wal
├── 000000002
└── checkpoint.00000001
└── 00000000data 下每一个文件夹称之为一个 block,虽然名字看起来像是乱码,却是按照时间顺序生成的。每个 block 中包含一个 chunks 目录,里面分段保存当前时段的指标样本。meta.json 记录了时段起止时间等元信息,index 记录各类标签到指标样本的索引关系,tombstones 记录了 chunks 中已经被删除的样本数据。
最新的数据主要保存在内存中。Prometheus 采到数据后会先写入 wal 日志,以防意外关机后丢失数据。每隔一段时间,Prometheus 会把数据写到 chunks_head 目录。等积累到一定数量的 chunk,Prometheus 就会生成对的 block 目录。
我们可以通过--storage.tsdb.path指定 data 目录的位置,通过--storage.tsdb.retention.time 和--storage.tsdb.retention.size指定指标样本数据的保存时间和最大磁盘点用空间。默认是保存15天,磁盘空间无限制。
以上就讲完采集和存储部分。下面进入激动人心的查询环节~
查询 PromQL
指标数据保存之好,就需要通过某种方式查询。关系型数据库使用 SQL 作为统一的查询语言。而 Prometheus 面向时间序列数据这一特殊场景,为了方便使用,它定义了自己专有的查询语言,称之为 PromQL。
主流的资料都会基于 Grafana 等可视化面板来讲解 PromQL。这种方式虽然直观,但隐藏了太多细节,反而不利于大家理解。今天我就直接从 API 入手,虽然没有图表高大上,但更容易理解。理解之后再用 Grafana 做面板就是小菜一碟了。
查询接口
首先,Prometheus 需要通过 HTTP API 进行查询。查询接口又分单点(instant)查询和范围(range) 查询两种。
所谓单点查询,就是查在某一时刻某一类指标的样本取值。它的接口路径是/api/v1/query,同时支持 GET 和 POST 两种调用方法。该接口有三个参数:
query=<string>PromQL 查询表达式,我们后面细说time=<rfc3339|unix_timestamp>要查询的时间点,支持 rfc3339 和 UNIX 时间戳两种格式。如果不指定,默认取当前时间。timeout=<duration>最大查询执行时间,超过了就放弃。一般不需指定。
如果是用 POST 方式查询,所有参数需要使用application/x-www-form-urlencoded编码。
假设我们要查询指标up在2015-07-01T20:10:51.781Z这一时刻的取值,可以发起如下请求:
curl 'http://localhost:9090/api/v1/query?query=up&time=2015-07-01T20:10:51.781Z'
{
"status" : "success",
"data" : {
"resultType" : "vector",
"result" : [
{
"metric" : {
"__name__" : "up",
"job" : "prometheus",
"instance" : "localhost:9090"
},
"value": [ 1435781451.781, "1" ]
},
{
"metric" : {
"__name__" : "up",
"job" : "node",
"instance" : "localhost:9100"
},
"value" : [ 1435781451.781, "0" ]
}
]
}
}这里的时间使用的 rfc3339 格式,方便展示。返回结果的data字段又分成resultType 和result 两部分。前者表示结果类型。据我所知,对于单点查询,它的结果类型应该只能是vector,也就是说一维指标数组。在上例中,因为指标名为up,所以会返回该指标下所有标签组合在这一时刻的样本对象。样本对象中的metric会保存标签信息,value 会保存样本毫秒时间戳和样本值。这里的[1435781451.781,"0"]通常称之为Scalar。
大家再想想,同一个指标针对不同的标签组合会形成一个数组;给定一种标签组合,它跟采集时间点又会形成一个新的数组。所以从指标名到样本 Scalar 是一个二维数组。我们称这个二维数组为 metric。但是在单点查询中,因为指定了时间点,所以结果是一维数组,也就是 vector。
在实际场景中,很少用到单点查询,更多地是用范围查询。范围查询使用单独的接口
/api/v1/query_range参数方面是把单点中的时间点time参数换成了如下表示时间范围的参数:
start=<rfc3339|unix_timestamp>: 开始时间,包含end=<rfc3339|unix_timestamp>: 结束时间,包含step=<duration|float>: 查询时间步长
开始和结束时间很好理解,但时间步长有什么用呢?我们在查询 Prometheus 时更多地是关心某指标在一段时间内的变化趋势。因为本身就是采样观测,我们不需要每次都看所有的数据。
假设我们查询从2015-07-01T20:10:30.781Z开始到2015-07-01T20:10:40.781Z为止的指标数据。因为只有10秒钟的时间,我们可以把步长指定为2秒,这样一来query_range 接口会返回如下时间点的观测数据:
2015-07-01T20:10:30.781Z
2015-07-01T20:10:32.781Z
2015-07-01T20:10:34.781Z
2015-07-01T20:10:36.781Z
2015-07-01T20:10:38.781Z
2015-07-01T20:10:40.781Z如果我们把步长定为1秒,就会得到10条数据。但如果我们的查询时段是从2015-07-01T20:10:30.781Z 到2015-07-01T20:11:30.781Z,这就没有必要将时间步长设为2s,调大一点也没关系,不会影响我们对指标趋执的判断。比如可以设置为一分钟。这样从10点到11点就会分成60段, Prometheus 会返回 61 条观测数据(因为包含两端的起止时间点)。
好了,给大定展示一个范围查询的例子:
curl 'http://localhost:9090/api/v1/query_range?query=up&start=2015-07-01T20:10:30.781Z&end=2015-07-01T20:11:00.781Z&step=15s'
{
"status" : "success",
"data" : {
"resultType" : "matrix",
"result" : [
{
"metric" : {
"__name__" : "up",
"job" : "prometheus",
"instance" : "localhost:9090"
},
"values" : [
[ 1435781430.781, "1" ],
[ 1435781445.781, "1" ],
[ 1435781460.781, "1" ]
]
},
{
"metric" : {
"__name__" : "up",
"job" : "node",
"instance" : "localhost:9091"
},
"values" : [
[ 1435781430.781, "0" ],
[ 1435781445.781, "0" ],
[ 1435781460.781, "1" ]
]
}
]
}
}这里的resultType变成了matrix。因为对于每一种指标+标签组合,它的values都对应一组数样本值,在逻辑上是一个二维表,所以是 matrix。
时间点对齐
细心的朋友会可能会发现,查询的时间点跟采集的时间没有任何关联。我们在前面讲过, Prometheus 会根据配置好的时间间隔,定时采集指标样本。但是我们在查询的时候可以任意指定时间,而且还能根据起止时间和步长生成一列时间点来要求 Prometheus 返回数据。
显然,Prometheus 不可能每次都在我们指定的时间点采集样本。我们以下图为例讲解。
m1 +-----+-----+-----+-----+-----+-----+-----+
m2 +-----+--⚬--+--⚬--+--⚬--+--⚬--+--⚬--+-----+
m3 +-----+-⚬---+-⚬---+-⚬---+-⚬---+-⚬---+-----+
m4 +-----+---⚬-+---⚬-+---⚬-+---⚬-+---⚬-+-----+
| | | | |
| | | | |
q1 *-----*-----*-----*-----* 最上面的四条线表示 Prometheus 的采集时刻。每个加号表示在该时间点采集到一个样本。不同的指标开始采集的时间点可能不同,而且在分布式环境中,就连采集时间间隔也不能保证完全一样。所以采集样本的时间点不可能整齐划一。
最下面表示查询时间范围,每个星号表示一个时间点,这些是根据步长精确计算出来的。我们希望 Prometheus 能返回对应时间点的数据。在上例中,只有指标m1的采集时间能跟查询时间点对上,其他指标的时间点都是错开的。这个时候 Prometheus 需要按照一种统一的方式来选一个替代值来返回。
Prometheus 的选法就是选择在查询时间点之前且离查询时间最近的采样点返回。也就是说,在上图中,Prometheus 会依次选择⚬左边最近的+来近似表示该时间点的样本值。但这种近似也不是没有限制。如果某一时该前面最新的样本值距离该时该已经超过五分钟,Prometheus 就会认为该项指标采集出现异常,不再返回对应的近似值。
基础查询
以上是 PromQL 查询接口的基本概念和用法。现在继续说 PromQL 的功能和语法。
第一个功能是过滤指标。我们日常采集的指标有千千万,但不同的人观注的指标各不相同。我们只需要查询相看的指标就可以了。这就需要为接口调用指定query参数。
最简单的 PromQL 查询是返回某指标的所有样本集。比如查看http_requests_total指标的所有样本:
query=http_requests_total后续为行文方便,统一省略
query=部分,只写 PromQL 表达式
Prometheus 会遍历所有status和handler的取值组合,每一种组合对应一个时间序列。这种查法通常没什么用。全返回跟全不返回也没什么区别。
SRE通常会观注线上报错情况,所以需查看status为5xx的指标样本,他可以写成:
http_requests_total{status="5xx}如果还想同时查询4xx样本,则需要使用正则表达式:
http_requests_total{status=~"5xx|4xx"}除了=~肯定匹配,Prometheus 还支持否定匹配。status!~"5xx"会匹配到所有状态码不是5xx的指标。
如果只想看特定接口,则可以继续添加标签过滤条件:
http_requests_total{status=~"5xx|4xx", handler="/login"}Prometheus 收到查询后会选根据起止时间确定要读取哪些区块,然后根据 block 的 index 索引文件计算出需要的指标集,最后根据时间点从 chunks 中查询对应的样本数据。
从查询过程来看,查询跨度越大,需要扫描的区块就越多。标签过滤条件越少,查出来的指标也就越多,相应的返回的样本数据也就越多。这也意味着查询耗时越久。
在日常监控中,很多指标都需要展示环比数据,以此来判断当前状态是否有问题。最常用的就是周环比,也就是异示上周同期的指标水平。这可以使用offset语法来实现。
cpu_load1{instance="foo"} offset 1w上例中会查询主机foo在上周当前时刻的cpu_load1指标。
Prometheus 支持多种时间单位,不光是offset可以使用,前文的step参数也可以。
- ms - 毫秒
- s - 秒
- m - 分钟
- h - 小时
- d - 天 - 24小时
- w - 周 - 7天
- y - 年 - 365天
大家可以按需选用,非常方便。
向量运算
通过查询接口,我们可以得到某指标在不同标签组合下的多组样本时间序列。这里的每一组样本称之为 Instant vector,中文直译为『即时向量』。向量之间可以做一些数学运算。比如假设我们有三台机器,已经采集了它们的内存使用指标:
node_memory_total_bytes{instance="app1"}
node_memory_total_bytes{instance="app2"}
node_memory_free_bytes{instance="app1"}
node_memory_free_bytes{instance="app2"}那么我们可以通过如下查询得到多组样本数据,表示当前使用的交换分区容量:
node_memory_total_bytes{instance=~"app.*"} - node_memory_free_bytes{instance=~"app.*"}这里的-表示对于给定的instance标签值,查到对应的node_memory_SwapTotal_bytes 和 node_memory_SwapFree_bytes 两组样本。然后依次将对应时间点的样本数据相减,形成一组新样本序列。
假设原始样本数据如下:
node_memory_total_bytes{instance="app1"} -> [10, 10, 10, 10, 10, 10]
node_memory_total_bytes{instance="app2"} -> [10, 10, 10, 10, 10, 10]
node_memory_free_bytes{instance="app1"} -> [ 9, 9, 9, 8, 5, 1]
node_memory_free_bytes{instance="app2"} -> [10, 10, 10, 10, 10, 8]那么上例的查询结果是:
{instance="app1"} -> [1, 1, 1, 1, 2, 5, 9]
{instance="app2"} -> [0, 0, 0, 0, 0, 0, 2]我们还可以计算内存使用率指标:
(1 - node_memory_free_bytes{instance=~"app.*"} / node_memory_total_bytes{instance=~"app.*"}) * 100这里用到了除法,同样是向量对应的值分别相除。node_memory_free_bytes/node_memory_total_bytes 的结果是另一列向量:
{instance="app1"} -> [0.9, 0.9, 0.9, 0.8, 0.5, 0.1]
{instance="app2"} -> [1.0, 1.0, 1.0, 1.0, 1.0, 0.8]对应的1-R*100则是对向量中的每一个样本值i都计算一遍,将结果组成一个新的向量:
{instance="app1"] -> [10, 10, 10, 20, 50, 90]
{instance="app2"] -> [ 0, 0, 0, 0, 0, 20]向量支持的数学运算符有:
+加法-减法*乘法/除法%取模^乘方
除了数学运算,向量还支持比较运算。比如有向量 a=[1,3,2] 和 b=[4,2,1],则 a < b 的结果是[1,2]。因为a中的3大于b中的2,所以被排除。PromQL 比较运算默认是过滤样本数据,不符合条件的会被剔除。如果想或取比较的逻辑结果,可以加上bool修饰符。
a < bool b 的结果是[1,0,1],对应每个样本的比较运算结果。
通过比较运算,我们可以过滤到样本中的异常值,防止干扰。
向量匹配
细心的读者可能会发现一个问题。两个向量做运算是针对每个对应的取值做运算,结果形成一个新的向量。这就要求两个向量的样本数要一一对应。如果它们的样本数不相同会怎么样呢?
这就需要使用向量匹配语法。
假设我们的原始指标如下:
method_code:http_errors:rate5m{method="get", code="500"} 24
method_code:http_errors:rate5m{method="get", code="404"} 30
method_code:http_errors:rate5m{method="put", code="501"} 3
method_code:http_errors:rate5m{method="post", code="500"} 6
method_code:http_errors:rate5m{method="post", code="404"} 21
method:http_requests:rate5m{method="get"} 600
method:http_requests:rate5m{method="del"} 34
method:http_requests:rate5m{method="post"} 120为简化分析,仅展示向量的一个样本。
在这里method_code:http_errors:rate5m与method_code:http_requests:rate5m并不一一对应。
如果我们要查询当前时间点状态码为500的请求占比,需要写成如下表达式:
method_code:http_errors:rate5m{code="500"} / ignoring(code) method:http_requests:rate5m因为method_code:http_requests:rate5m没有code标签,我们需要通过ignoring(code) 来忽略这一匹配条件。如若不然,Prometheus 会尝试查找code="500"的method_code:http_requests:rate5m。这个指标不存在,也就不会返回结果。忽略掉code之后的结果是:
{method="get"} 0.04 // 24 / 600
{method="post"} 0.05 // 6 / 120虽然忽略掉了code,但 Prometheus 还是根据method标签匹配出对应的指标。这里的ignoring支持略多个标签条件。如果只想针根据特定标签匹配指标,则可以用on。
比如我们想查看所有错误请求的占比情况,也就是列出method和code的不同种组合。上例中method_code:http_errors:rate5m的get和post都对应两组指标,但method:http_requests:rate5m 对应的method各只有一个值。所以我们需要以左边为准,也就以method_code:http_errors:rate5m 为准。有点类似数据库里的 left join。
method_code:http_errors:rate5m / ignoring(code) group_left method:http_requests:rate5m因为有group_left,所以 Prometheus 在匹配的时候会以method_code:http_errors:rate5m 为基准,重复使用右边method:http_requests:rate5m对应的指标值。
{method="get", code="500"} 0.04 // 24 / 600
{method="get", code="404"} 0.05 // 30 / 600
{method="post", code="500"} 0.05 // 6 / 120
{method="post", code="404"} 0.175 // 21 / 120如果是右值少而左值多,则可以使用group_right。在此就不展开说明了。
聚合运算
除了上述基本运算,PromQL 还提供了一组聚合函数。它们都是针对一组向量,会把每个时间点上的值聚合起来,计算结果形成一一个新的向量。这里举几个常用的聚合操作:
sum求合min最大值max最小值avg平匀值count计数bottomk后多少名指标topk前多少名指标
取合操作支持通过by和without指定聚合维度。假设http_requests_total有三个标签: application,instance和group,我们希望按照application和group分组汇总请求总数,可以这样写:
sum without (instance) (http_requests_total)也可以使用by修饰符:
sum by (application, group) (http_requests_total)without是黑名单,by是白名单。
如果想看 HTTP 请求总数,可以去掉聚合维度:
sum(http_requests_total)如果想查看请求数最多的前五个实例,可以使用topk:
topk(5, http_requests_total)这里再次强调,以上聚合函数是针对不同标签取值维度上的聚合,不是在时间维度上的聚合。所以它们的结果还是一个向量。
Counter 操作
对于 counter 类型的指标,我们通常会计算它们的速度。比如 http_requests_total 是记录每个时刻已经处理了多少请求。但如何才能计算数请求的 QPS 呢?我们需要选一段比较小的时间段 ,然后确定 http_requests_total 在该时段开始和结束时的取值和 ,最终计算平均请求速度为:。
对于每一个观察点,我们都需要做上述计算。在 PromQL 中可以通过rate函数计算。假设取一分钟,那么对应的平均速度就是:
rate(http_requests_total{application="api"}[1m])这里使用[1m]表示时间段。可个查询过程如下:
- Prometheus 根据
start/end/step计算出观测时间点 - 对于每个时间点,依次选取该时间点前一分钟内的所有样本,这会形成一个二维数组
- 对于每个时间点上的样本组合,选取第一个和最后一个样本,计算平均斜率(也就是速度)
对于给定的指标向量,rate的计算结果是一个新的向量。需要注意,rate函数会取两头的样本值计算结果。如果考察时间段较长,那么中间的尖峰数据就会被平均到。所以说rate 比较适合那些平滑变化的指标量。如果指标可能有突然的尖峰,则可以考虑使用irate函数。该函数在计算时会选择最后两个相临的样本计算斜率,尖峰就不会被平均掉。
Histogram 操作
对于 histogram 类型,我们可以计算指标的分位数。比如计算http_request_duration_seconds 指标的 90 分位数
histogram_quantile(0.9, rate(http_request_duration_seconds_bucket[10m]))注意,这里需要指定对应的_bucket指标,Prometheus 会自动计算分位数。如果需要针对不同的维度来计算聚合分位数,可以这样:
histogram_quantile(0.9, sum by (job, le) (rate(http_request_duration_seconds_bucket[10m])))这里使用sum by时一定不要漏掉le维度,不然sum的结果就不是 histogram 了。
可视化
了解了 PromQL 的概念,我们终于可以做监控面板了。基本上现在都用 Grafana 展示指标信息。我们就以它为例介绍可视化方面的的基础知识。
基础操作
先上一张效果图
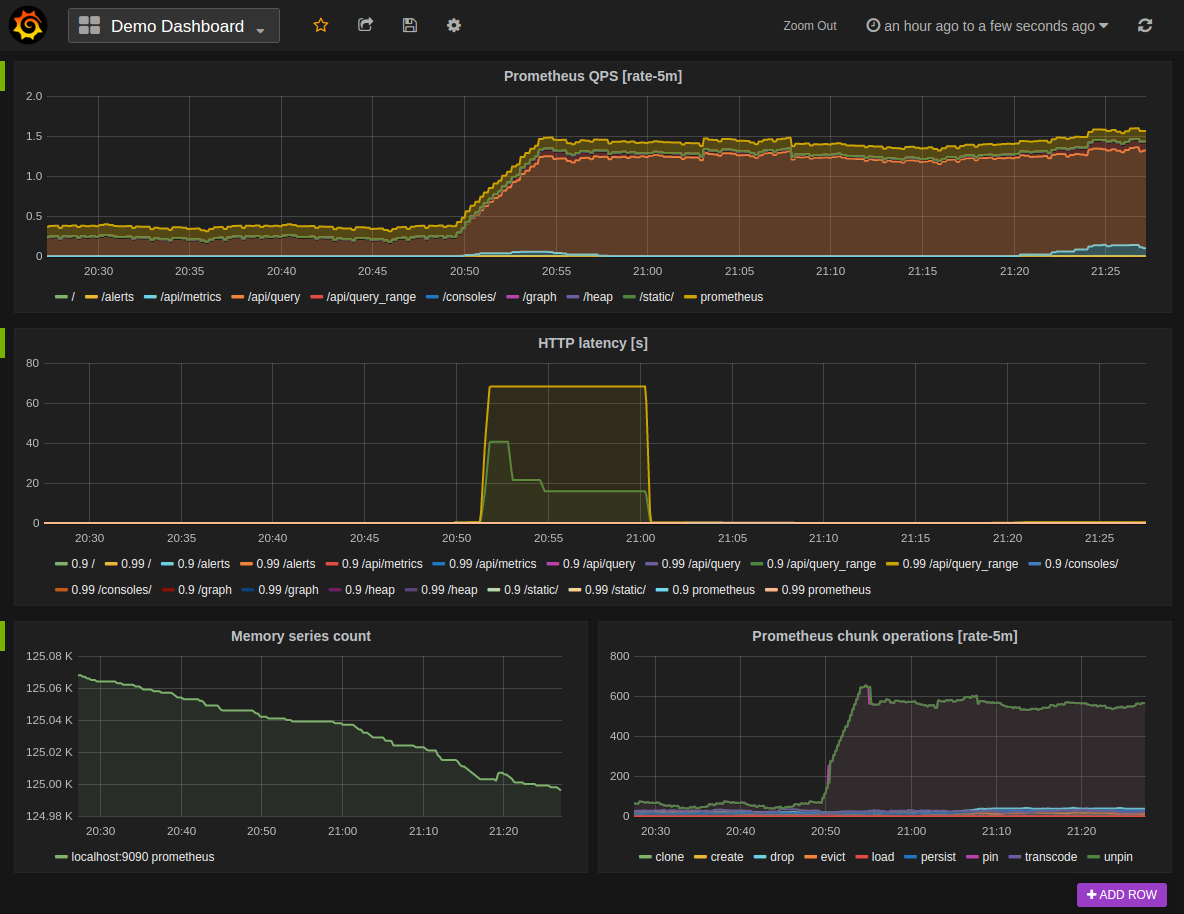
安装完 Grafana 之后,我们首先得添加数据源。Grafana 是一款通用的数据可视化工具, Prometheus 只是它支持平台之一。另一种用的比较多的是 MySQL 数据源,我们后面会说。
添加数据源时类型选 Prometheus,最终进入如下界面

这里主要指定 URL 参数,也就是 Prometheus 的查询地址。如果 Prometheus 配置了登录验证,还需要在该页面填定登录信息。
添加数据源之后就可以创建图表了。
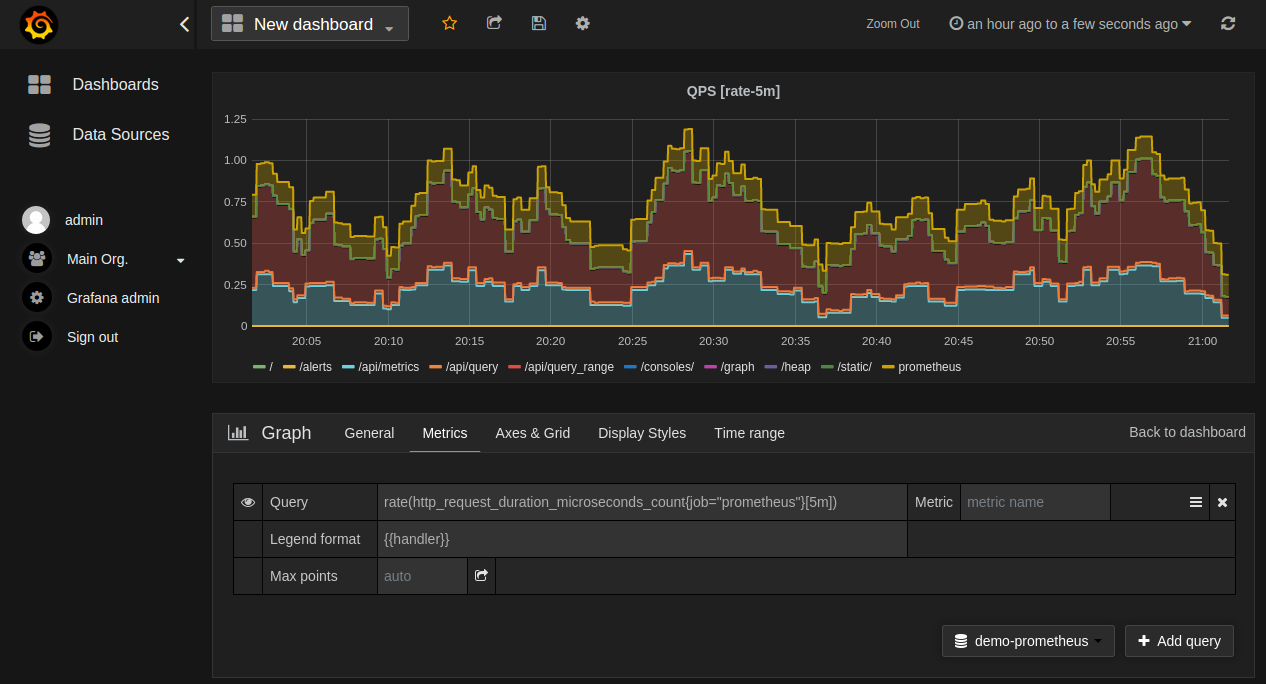
Grafana 支持很多种图表,大家可以参考官方网档。本文只讲最基本的内容。
新建图表首先要选数据源,然后是在 Metrics 页中新建查询,查询里要填 PromQL 表达式。查询接口所需要的起止时间、步长等 Grapha 会提供标准组件,我们不用关心。
在上图中,PromQL 查询是
rate(http_request_duration_microseconds_count{job="prometheus"}[5m])显然是在统计 HTTP 接口的请求速度,考察时间段是五分钟。
下面的 Legend format 表示每条指标曲线对应的名字,可以通过{{handler}}让 Grafana 自动填入对应的标签值。
其实五分钟的间隔有点大了,精度太低。可以调小一点。但调太小就会收集不到足够的样本。 rate函数要求最时间间隔不能低于抓取间隔的四倍,也就是说在指定时段内至少要用四个样本。所以 Grafana 在 7.2 版本引入了$__rate_interval变量,会自动根据数据源配置计算合适的时间间隔,建议大家直接使用。
自定义变量
说起变量,又是一个很大的主题。本节只能略讲一二。
我们可以到 dashboard 的配置 -> 变量页面来管理当前面板使用的变量。变量主要用于过滤指标。比如系统分为开发、测试和生产三个环境,那我们可以定义一个变量名为env,值为常量数组dev,test,prod。然后在采集指标时分环境打上env标签。
建好变量后 Grafana 就会在该面板上自动展示一个下拉菜单,里面有dev/test/prod三个选项。我们在查询指标时需要指定env标签:
rate(http_requests_total{application="api",env=~"$env"}[1m])这样能过选择不采单中不同的环境,就可以展示对应的监控图表,非常方便,也很酷。
除了写死变量取值外,很多时时候我们需要从指标中动态查询某个标签的值,然后自动生成下拉菜单。这在 Grafana 中需要用到 label_values 指令。比如我们想自动展示所有 HTTP 接口路径:
label_values(http_requests_total{env=~"$env"}, handler)Grafana 会调用 Prometheus 的 lables 接口4查询所有的标签取值,然后生成菜单。
注意一点,变量之间可以相互引用。上例中会根据$env的取值来查询对应环境的 HTTP 接口。
特别的,我们可以为 Prometheus 数据源创建指标。如果你在运维大型项目,可能需要多组 Prometheus 实例来收集海量指标。不同指标分布在不同的 Prometheus 服务上。每个服务对应一个数据源。这时候我们可以创建类型为 Prometheus 变量,指定数据源名字匹配规则,然后就可以在创建图表时在数据源一项引用这个变量。该图表就能展示多个 Prometheus 的指标数据。
MySQL 变量
最后说一下 MySQL 数据源在变量只的使用场景。
稍有规模的 IT 环境都需要配置数据库 DMDB,来管理当前所用的各类资源以及资源的组织关系。相关人员在查看面板时通常只关心某特定组织下的资源。这就需要根据 CMDB 来动态过滤指标了。
方案也很简单。先给 Grafana 添加 MySQL 数据源,让它能读取 CMDB 中的数据。如果用的不是 MySQL,可以搞一个同步任,定时将 CMDB 信息写入 MySQL。
然后就可以在 Grafana 创建查询型变量,指定数据源为刚才的 MySQL,这样就能在查询中填写 SQL 语句了。只要 SQL 能返回一列数据,Grafana 就能生成对应的展示菜单。这些查询可以配合其他变量实现分组织过滤资源等效果。
Grafana 内容非常丰富。这里只挑了我所理解的最有用的部分介绍给大家,也是管中窥豹。更多内容还请详细研究官方文档。
小结
没想到已经写了一万字,这个主题真是太庞大,动笔之前没有充分估计革命任务有这么艰巨。就是这一万多字里,感觉还有很多方面没覆盖到。可视化部分也比较简略,原本计划的告警部分只能作罢,因为这又是一个很大的主题。只能后面单独梳理了。但无论如何,这一万多字还是把一些基础、核心、有用的知识都覆盖到了。这里面有官网的知识,我自己的理解,也有我工作单位的实践,对于初学者算是比较综合的入门材料了。就此搁笔,欢迎大家留言讨论。