在浏览器中批量保存文件
涛叔最近接到一个业务需求,说是需要批量导出图片功能。Web 开发同学觉得应该把下载任务提交给服务端,由服务端完成打包,然后给出下载链接。我个人感觉这个功能可以直接在浏览器里实现。于是调研了一下,找到了一个可行方案。今天整理出来,分享给大家。
本文介绍的方案使用了 Chrome 专有 API,所以无法在 Firefox 浏览器下正常运行😂
我最先想到的就是使用 File System Access API。我谁想着通过 File System Access API 可以拿到本地某个文件夹的写权限,然后在该文件夹中通过 JavaScript 创建并保存需要导出的图片。但是经过调研后发现,File System Access API 只能通过 showSaveFilePicker() 保存文件,而且每次调用都会弹出文件选择对话,让用户确认。所以无法实现批量保存的功能。
既然一次只能保存一个文件,那就必须把所有图片打包成一个文件来保存。所以我就想到了 Zip 文件格式。但是,业务方提出一次导出的图片总体积可能会达到好几个G的量级。如果我们纯在内存操作,那就有可能会耗尽系统的内存。所以一定要设计一种流式的方案。于是我想到了 Streams API。
在尝试使用流式处理之前,我还得先弄清楚 Zip 文件格式是否支持流式处理。一番搜索后,我找到了 Zip 文件的结构:
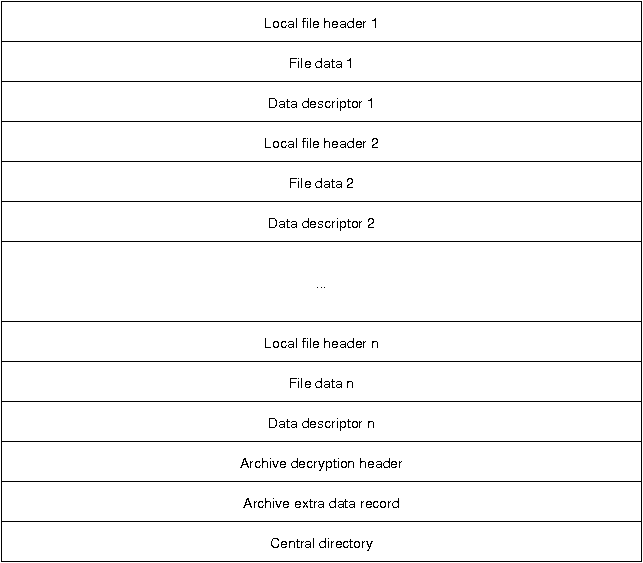
图片来自 Florian Buchholz 的文章 The structure of a PKZip file。
简单来说,Zip 是一种打包模式,每个文件都包含三个部分:
- Local file header
- File data
- Data descriptor
等所有数据都保存之后,还需要在文件结尾追加三部分信息:
- Archive description header
- Archive extra data record
- Central directory
其中最后的 Central directory 保存每个文件目录等作息。它们的引用关系如下:

图片来自 David Fifield 的文章 A better zip bomb
到这里,我就可以确定 Zip 文件确实支持流式处理。
现在思路就很明确了。首先,我们通过 showSaveFilePicker 接口创建一个新文件,并获取对应的 WriteStream,然后创建一个 Zip 文件 Stream 并与之绑定,最后依次使用 fetch 下载图片,把对应的 ReadeStream 重定向到前面的 Zip Stream。
创建文件的操作比较简单:
const opts = {
types: [{
description: 'Zip file',
accept: {'application/zip': ['.zip']},
}],
};
let file = await window.showSaveFilePicker(opts);
let writeStream = await file.createWritable();然后就是创建 Zip 文件流。这里我借用了 StreamSaver.js 的实现。
const zipStream = new ZIP({
async pull (ctrl) {
const url = 'https://d8d913s460fub.cloudfront.net/videoserver/cat-test-video-320x240.mp4'
const res = await fetch(url)
const stream = () => res.body
const name = 'streamsaver-zip-example/cat.mp4'
ctrl.enqueue({ name, stream });
ctrl.close();
}
})
await zipStream.pipeTo(writeStream);因为是纯前端代码,所以大家可以在 Chrome 中体验该方案的使用效果。
因为 Firefox 不支持 File System Access API,所以本文介绍的方案没法在 Firefox 内运行。如果一定要支持 Firefox,则可以使用前面提到的 StreamSaver.js。
StreamSaver.js 的思路也是非常巧妙。它使用了 service worker 拦截 fetch 调用的并通过 respondWith 将 Zip 数据流写入要下载的文件中。该方案的优点是支持 Firefox 等浏览器,但缺点也很明显,整个实现非常复杂,需要处理与 service worker 的通信和 worker 保活等逻辑。比较而言,基于 File System Access API 的方案就明显清真不少😄
最后提醒一下,Zip 格式并没有规定文件名的编码。如果导出的文件名有中文,可能会出现乱码。所以,如果是 Windows 平台,推荐转换成 GBK 编码。本文用到的 zip-stream 库只支持 UTF-8 编码。大家有需要的话得自己订制了😄